Paketempfang: DHL-App erhält neue Optionen für Push-Benachrichtigungen
Von Ingo Pakalski — 18. März 2026 um 08:44
Nach einem Update bietet die DHL-App neue Einstellungen für Push-Benachrichtigungen. Das soll den Paketempfang angenehmer machen.
Die DHL-App informiert über den Status der Zustellung von Paketen.Bild:
Rudolf Wichert / DHL Group
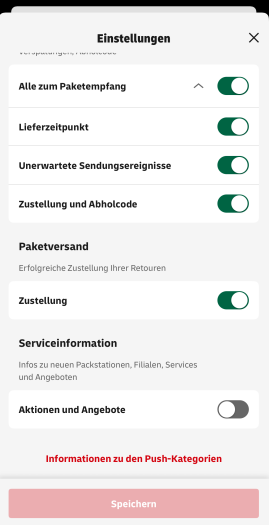
Die DHL Group hat die DHL-App für iOS aktualisiert und stellt veränderte Einstellungen für Push-Benachrichtigungen rund um den Empfang von Paketen zur Verfügung. Beim Paketversand gibt es neuerdings drei Unterkategorien, um sich über den weiteren Fortschritt beim Empfang von Paketen zu informieren.
Die neuen Einstellungen gibt es in der DHL-App nur, wenn die App mit einem DHL-Konto verwendet wird. Zwar gibt es auch Push-Benachrichtigungen, wenn die App ohne Konto verwendet wird, eine genauere Konfiguration fehlt dann jedoch.
So lassen sich bei Bedarf alle Push-Benachrichtigungen rund um den Lieferzeitpunkt abwählen. Wenn die Option aktiv ist, gibt es Mitteilungen zum erwarteten Liefertag, einen Hinweis am Liefertag und dann noch einmal 15 Minuten vor der Zustellung. Das 15-Minuten-Zeitfenster wird in der Praxis aber nicht immer eingehalten, vielfach kommt ein solcher Hinweis mit einem anderen Zeitvorlauf.
Neue Einstellungen in der DHL-App
Dann lassen sich Benachrichtigungen aktivieren, falls es zu unerwarteten Ereignissen bei der Zustellung kommt. Also, falls sich die Zustellung verzögert, es zu einer Rücksendung kommt oder wenn ein Paket beschädigt wurde. Eine dritte Kategorie deckt den Bereich Zustellung und Abholcode ab.
Dabei geht es darum, über eine Zustellung informiert zu werden, auch etwa, wenn das Paket am vereinbarten Ablageort deponiert, bei einem Nachbarn abgegeben oder in einer Packstation hinterlegt wurde. Beim Versand von Paketen gibt es keine weitere Unterteilung, sondern nur eine Rubrik für alle Benachrichtigungen dazu.
Wer die DHL-App auf einem Android-Gerät verwendet, kann die neuen Optionen bisher nicht verwenden. Während die DHL-App für iOS diese Woche aktualisiert wurde, stammt das letzte Update für Android im Play Store vom 27. Januar 2026. In der Web-Version des Play Store wird ein Update vom 16. März 2026 genannt, dieses ist aber auf mehreren Android-Geräten der Redaktion noch nicht verfügbar.
Bild 1/4: Diese neuen Optionen gibt es in der DHL-App für iOS. (Bild: DHL Group/Screenshot: Golem)
Bild 2/4: Das bedeuten die jeweiligen Benachrichtigungs-Kategorien. (Bild: DHL Group/Screenshot: Golem)
Bild 3/4: Das bedeuten die jeweiligen Benachrichtigungs-Kategorien. (Bild: DHL Group/Screenshot: Golem)
Bild 4/4: In der DHL-App für Android gibt es hingegen diese Optionen für Push-Benachrichtigungen. (Bild: DHL Group/Screenshot: Golem)
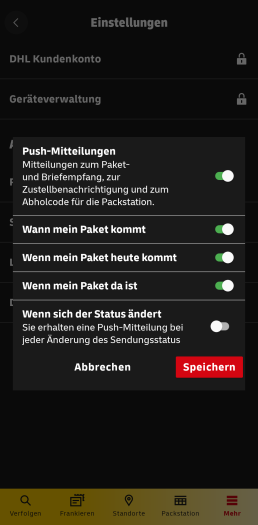
In der Android-Version der DHL-App gibt es vier andere Mitteilungskategorien. Bei Bedarf gibt es eine Information zum Zustelltag, einen Hinweis bei einer heutigen Zustellung, eine Benachrichtigung bei erfolgreicher Zustellung und bei Bedarf gibt es Push-Mitteilungen bei allen Änderungen des Sendungsstatus. Eine gesonderte Konfiguration für die Zustellung eines versendeten Pakets gibt es nicht.
Pentagon-Pläne: KI-Modelle sollen mit Geheimdienstdaten trainiert werden
Von Nils Matthiesen — 18. März 2026 um 08:22
Das Pentagon erwägt, Sprachmodelle von OpenAI und xAI direkt mit geheimen Militärdaten zu trainieren, um die Treffsicherheit zu erhöhen.
US-Militär plant geheimes KI-Training. (Symbolbild)Bild:
Andrew Harnik/Getty Images
Das US-Kriegsministerium plant den Aufbau gesicherter Umgebungen, in denen KI-Unternehmen ihre Modelle mit hochgradig sensiblen und klassifizierten Informationen trainieren können. Wie das MIT Technology Review berichtet , sollen militärspezifische Versionen von generativen KI-Modellen entstehen, die direkt auf Geheimdienstberichten und Schlachtfeldbewertungen basieren. Bisher nutzen Dienste wie das Pentagon zwar bereits Modelle wie Anthropics Claude in gesicherten Umgebungen, um Fragen zu klassifizierten Inhalten zu beantworten – ein direktes Training auf diesen Daten wäre jedoch ein qualitativ neuer Schritt.
Ziel der Initiative ist es, die Genauigkeit der KI bei militärischen Aufgaben massiv zu steigern. Ein US-Verteidigungsmitarbeiter gab an, dass die Modelle durch den Zugriff auf interne Daten effektiver bei der Analyse von Zielen oder der Verknüpfung historischer Kontexte mit neuen Informationen werden könnten.
Dies geschieht vor dem Hintergrund einer neuen Agenda des Verteidigungsministers Pete Hegseth, die USA zu einer AI-first-Kriegsmacht zu machen. Entsprechende Abkommen zur Nutzung von Modellen bestehen bereits mit OpenAI und Elon Musks xAI.
Risiken durch Daten-Leaks innerhalb der Behörden
Das Vorhaben birgt jedoch erhebliche Sicherheitsrisiken. Experten wie Aalok Mehta vom Center for Strategic and International Studies warnen davor, dass sensible Informationen – etwa Klarnamen von Agenten – durch das Training tief in die Gewichte des Modells eingebettet werden könnten. Falls verschiedene Abteilungen mit unterschiedlichen Sicherheitsfreigaben auf dasselbe Modell zugreifen, bestehe ferner die Gefahr, dass die KI geheime Informationen an unbefugte Nutzer innerhalb des Apparats preisgibt. Ein "Auslaufen" der Daten in das öffentliche Internet gilt bei entsprechender Infrastruktur hingegen als weniger wahrscheinlich.
Das Training soll in akkreditierten Rechenzentren stattfinden. Während das Pentagon Eigentümer der Daten bleibt, könnten Mitarbeiter der KI-Firmen in Ausnahmefällen Zugriff erhalten, sofern sie über die notwendigen Sicherheitsüberprüfungen verfügen. Bevor das Training mit echten Geheimdaten beginnt, will das Militär jedoch evaluieren, wie leistungsfähig die Modelle bereits beim Training mit nicht-klassifizierten Daten, etwa kommerziellen Satellitenbildern, agieren.
KI bereits im Kampfeinsatz
Generative KI wird bereits aktiv vom US-Militär genutzt, unter anderem zur Priorisierung von Ziellisten bei Konflikten. Bisherige Anwendungen beschränken sich oft auf Computer-Vision-Modelle zur Objekterkennung in Drohnenaufnahmen. Die Ausweitung auf Large Language Models, die auf riesigen Mengen an Text, Audio und Video der Geheimdienste trainiert werden, markiert allerdings eine neue Stufe der militärischen KI-Integration. Welche spezifischen Fähigkeiten damit genau entwickelt werden, hält das Pentagon aus strategischen Gründen aber unter Verschluss.
Golem-Konferenz Rack & Stack 2026: Digitale Souveränität nicht bremsen, sondern anschieben!
Von Golem.de — 18. März 2026 um 08:00
Die Notwendigkeit für digitale Souveränität ist auf höchster politischer Ebene angekommen – aber die Warner stehen schon bereit. Unsere Konferenz Rack & Stack liefert überzeugende Gegenargumente.
Nur noch rund einen Monat bis zur Rack & Stack, der Golem-Fachkonferenz zu digitaler Souveränität!Bild:
Martin Wolf / Golem
Die Europäische Kommission will im April ihr Paket zur digitalen Souveränität vorlegen. Das Ziel: weniger Abhängigkeit von US-Cloud- und KI-Anbietern. Allerdings sind die europäischen Unternehmen, die davon profitieren sollen, die lautesten Skeptiker . Ein schneller Wechsel weg von US-Plattformen sei operativ nicht machbar, heißt es. Dieser brauche Zeit – und die koste Marktanteile.
Auf der Rack & Stack dreht sich zwei Tage lang alles um den Ausstieg aus der Cloud, um Datensouveränität und Resilienz. Mehr als ein Dutzend hochkarätige Speaker berichten direkt aus der Praxis. Garantiert buzzwordfrei, ohne Produktshows. Keine Visionstexte, sondern Erfahrungsberichte aus dem laufenden Betrieb. Mit ehrlichen Learnings, klaren und pragmatischen Botschaften.
Digitale Souveränität wird häufig abstrakt diskutiert. Doch wie lässt sie sich in gewachsenen IT-Landschaften konkret umsetzen? Der Vortrag von Maximilian Walz , der den Bereich Technology Transformation im Chief Sovereignty Office von T-Systems verantwortet, zeigt anhand von Transformationsprojekten, wie Unternehmen technologische Abhängigkeiten analysieren, priorisieren und gezielt reduzieren können.
Dabei beantwortet er praktische Fragen wie: Welche Ebenen sind tatsächlich steuerbar? Wo bleiben bewusste Abhängigkeiten bestehen? Und welche organisatorischen sowie technischen Maßnahmen erhöhen Resilienz und Handlungsfähigkeit nachhaltig?
So gelingt digitale Unabhängigkeit!
Auch in den weiteren Vorträgen, unter anderem von Jürgen Geuter (alias tante; mit aktuellem IMHO bei Golem ) und Kurt Garloff, geht es darum, wie Organisationen Souveränität technisch umsetzen, etwa durch automatisierte Rechenzentrumsinfrastruktur, eigene Plattformen ohne Hyperscaler oder föderierte Anwendungsmodelle, die zentrale Kontrollpunkte vermeiden.
Die Rack & Stack 2026 zeigt, wie digitale Unabhängigkeit gelingen kann. Lasst uns zusammenkommen und über eines der aktuell wichtigsten IT-Themen reden!
Die Ukraine akzeptiert EU-Hilfe bei der Reparatur der Druschba-Pipeline. Ungarn blockiert weiterhin Milliardenkredite für Kiew. Der Zeitdruck wächst.
Die Druschba-Pipeline, die russisches Erdöl [1] durch die Ukraine nach Ungarn und in die Slowakei befördert, ist in den vergangenen Monaten ein Zankapfel für die drei Länder gewesen. Jetzt soll die Pipeline, die bei einem Drohnenangriff beschädigt wurde, doch repariert werden.
Der ukrainische Präsident Wolodymyr Selenskyj hat jetzt dafür grünes Licht gegeben. Einer EU-Expertenkommission soll es gestattet werden, dabei zu helfen.
In einem Schreiben an EU-Ratspräsident [2] António Costa und Kommissionspräsidentin Ursula von der Leyen teilte er am Dienstag mit, sein Land nehme sowohl die technische Unterstützung als auch die angebotenen Finanzmittel an.
Selenskyj hat aber auch klargemacht, dass er den Weitertransport von russischem Öl durch sein Land grundsätzlich ablehnt.
Selenskyj: Gegen russischen Öltransit, aber unter Druck
Bei einer Pressekonferenz in Kiew fand der ukrainische Staatschef laut Bloombergdeutliche Worte [3]:
"Ich sage ganz einfach: Wenn wir beschlossen haben, die russischen Öllieferungen wieder aufzunehmen, dann möchte ich, dass sie wissen, dass ich dagegen bin."
Er zog zudem einen Vergleich zu den USA: Es sei widersprüchlich, einerseits Washington für die Lockerung von Russland-Sanktionen zu kritisieren und andererseits die Ukraine zum Öltransit zu zwingen.
Dennoch blockiere er die Reparatur nicht – die Entscheidung sei letztlich eine europäische.
Ungarn und Slowakei halten Milliardenhilfen zurück
Auslöser des Konflikts ist ein russischer Drohnenangriff Ende Januar, der die Druschba-Pipeline in der Westukraine traf. Seitdem fließt kein russisches Rohöl mehr nach Ungarn und in die Slowakei.
Als Reaktion blockiert Budapest ein EU-Kreditpaket über 90 Milliarden Euro für die Ukraine sowie neue Russland-Sanktionen. Ministerpräsident Viktor Orbán brachte seine Haltung auf eine einfache Formel: "Wenn es kein Öl gibt, gibt es kein Geld."
Selenskyj nannte [5] dieses Vorgehen "Erpressung" und verwies darauf, dass Ungarn schon lange vor dem Pipeline-Vorfall regelmäßig EU-Hilfen für Kiew verzögert oder verhindert habe.
Kiew wies ungarisches Team zuvor ab
Vor der Einigung mit Brüssel hatte die Ukraine ein von Budapest angekündigtes Inspektionsteam zurückgewiesen. Der stellvertretende ungarische Energieminister Gabor Czepek hatte laut Bloomberg erklärt, eine Delegation leiten zu wollen, die in Kiew Gespräche zur Reparatur der Pipeline führen solle.
Das stieß in Kiew allerdings auf wenig Gegenliebe. Das Außenministerium erklärte, man könne die Gruppe nicht als Delegation anerkennen. Schließlich besitze sie keinen offiziellen Status. Auch seien keine Treffen geplant gewesen.
Sprecher Heorhii Tykhyi kommentierte lakonisch [6]: "Jede Person aus den Schengen-Ländern kann zu touristischen Zwecken in die Ukraine einreisen".
Vollständige Reparatur benötigt noch Wochen
Laut Selenskyj arbeiten ukrainische Fachleute bereits an einer Umgehungsleitung, die in rund anderthalb Monaten einsatzbereit sein soll. Und wie Bloomberg unter Berufung auf anonyme Quellen berichtet, könnte die direkte Reparatur des beschädigten Abschnitts etwa einen Monat dauern.
"Dies wird eine vollständige Wiederherstellung des Ölflusses gewährleisten – natürlich vorausgesetzt, es kommt zu keinen weiteren Angriffen seitens Russlands", schrieb er an die EU-Spitzen.
Von der Leyen erklärte, europäische Fachleute stünden bereit, um sofort mit der Arbeit zu beginnen.
Ungarns Außenminister Péter Szijjártó wies den Vorschlag jedoch als "politisch motiviert" und mit Kiew abgestimmt zurück. Stattdessen forderte eine sofortige Wiederinbetriebnahme.
EU hält an Ausstieg aus russischem Öl fest
Costa und von der Leyen bekräftigten in ihrem Antwortschreiben das Ziel, sämtliche EU-Importe von russischem Öl bis Ende 2027 vollständig zu beenden. Ungarn und die Slowakei sehen diese Position nach wie vor kritisch und halten an der Verbindung nach Moskau fest. Doch sie können den EU-Fahrplan nicht durch ihr Veto stoppen.
Selenskyj forderte die EU zudem auf, die erste Tranche des Kreditpakets Anfang April freizugeben – unabhängig vom Fortschritt der Pipeline-Arbeiten.
URL dieses Artikels: https://www.heise.de/-11214731
Links in diesem Artikel: [1] https://www.heise.de/tp/article/Russland-Sanktionen-G7-plant-Verbot-von-Oellieferungen-statt-Preisobergrenze-11105393.html [2] https://www.bloomberg.com/news/articles/2026-03-17/ukraine-says-it-accepted-eu-mission-to-restore-druzhba-oil-flows [3] https://www.bloomberg.com/news/articles/2026-03-15/zelenskiy-says-tying-release-of-eu-funds-to-druzhba-blackmail [4] https://www.heise.de/tp/article/Tuerkei-und-Ungarn-hebeln-Europas-Energiekurs-aus-11113559.html [5] https://www.reuters.com/business/energy/ukraine-accepts-eu-offer-help-restore-druzhba-pipeline-2026-03-17/ [6] https://www.bloomberg.com/news/articles/2026-03-11/kyiv-rebuffs-hungarian-team-sent-to-check-pipeline-damage
Von links: Kommissar Dennis Eden (Stephan Zinner), Kommissarin Cris Blohm (Johanna Wokalek) und Léon Kamara (Yoli Fuller). | Bild: BR/die film gmbh/Susanne Bernhard
TV-Kritik: Verbrechen als Klassenfrage und die Relativitätstheorie der Gerechtigkeit – in einem philosophischen Polizeiruf siegt Nietzsche über Kant
"... doch leider hat man bisher nie vernommen,/ dass etwas recht war und dann war’s auch so!/
Wer hätte nicht gern einmal Recht bekommen?/ Doch die Verhältnisse, sie sind nicht so."
Bertolt Brecht, Dreigroschenoper (Über die Unsicherheit menschlicher Verhältnisse)
"Das klingt nach einem Cold Case, der gerade wieder heiß wird" – es fängt nicht gut an in diesem "Polizeiruf 110: Ablass [1]". Dem ersten Klischeedialogsatz folgen schnell noch ein paar Erklärbär-Sätze bis die Handlung langsam in Gang kommt und der Film seine Form findet.
Seine Pflichtaufgabe, dass die Leiche möglichst in den ersten fünf Minuten zu erscheinen hat, hatte dieser Krimi da schon gleich doppelt erfüllt: Zwei Leichen in nur drei Minuten. Eine Frauenleiche wurde nach zwei Jahren aus der Isar gefischt, das war der erwähnte Cold Case.
Zuvor war bereits ein schöner weißer alter 911er-Porsche durch die Münchner Nacht geknattert, mit 120, und hatte einen Realschullehrer auf dem Fahrrad erwischt. Nach der Fahrerflucht starb der Mann.
Falsche Geständnisse: Kann man Schuld und Sühne verkaufen?
Zwei Routinefälle, die bald gewisse Merkwürdigkeiten aufweisen: Die gefundene Frau wurde erwürgt und war zuvor vergewaltigt worden. Das Auffällige daran: Der Täter, ein afrikanischer Asylbewerber, sitzt längst ein, verurteilt nach seinem Geständnis für fahrlässige Tötung, unterlassene Hilfeleistung und angebliche Beseitigung der Leiche.
Im Fall der Fahrerflucht wird das Unfallauto bald gefunden, es war nach dem Unfall von den reichen und schnöseligen Bogenhausener Besitzern als gestohlen gemeldet worden. Auch hier wird der Täter schnell ermittelt und zeigt eine auffällige Bereitschaft, seine Tat zu gestehen. Die Beweislagen sind eindeutig.
Ein Muster kommt zum Vorschein, das sich langsam verdichtet und die beiden Fälle zusammenführt: Sind die Geständnisse in den Fällen überhaupt echt? Und wenn nein, warum sind sie falsch: Um eine eigene, schwerere Straftat zu vertuschen, oder die eines Anderen? Und wenn, ja warum? Übernehmen hier am Ende Arme und Schutzlose für Geld die Verantwortung für die Verbrechen der Reichen? Kann man Schuld und Sühne verkaufen?
Das ist die Grundsatzfrage, die sich den Ermittlern Clara Blohm (Johanna Wokalek) und Dennis Eden (Stephan Zinner) im Folgenden stellt.
Praktische Ratschläge fürs Leben und das Porträt der BRD als Klassengesellschaft
Dieser herausragende "Polizeiruf" – Regie und Drehbuch stammen vom Christian Bach und machen dieses Fernsehstück zu einem deutschen Autorenfilm im Fernsehen – wird durch dreierlei weit über den Durchschnitt des Fernsehkrimis hinausgehoben.
Es sind zum einen nicht zuletzt auch die kleinen Dinge, die in diesem Film besonders schön sind. Etwa das Kondom auf dem Rauchmelder, um diesen unschädlich zu machen, dass Eden ausgerechnet im Büro der Staatsanwältin entdeckt, die als Kettenaucherin auch im Büro ungestört genießen will. So gibt dieser Film auch praktische Ratschläge für unser aller Lebensalltag.
Es ist zum zweiten das Porträt der Bundesrepublik Deutschland als Klassengesellschaft. Als es die Ermittlerin Blohm bei der möglicherweise der Fahrerflucht schuldigen Kim, der Karrieretochter der Bogenhausener Karrierediplomatin, mit "dem Moralischen" versucht, beißt sie schnell auf Granit:
"Da geht jetzt ein Unschuldiger ins Gefängnis, auch wenn er es freiwillig tut. Und dann stell dir mal vor, sowas macht Schule – willst du wirklich in einer Welt leben, in der die Reichen davonkommen, nur weil die Armen den Kopf für Sie hinhalten?"
Die kühl-realistische Antwort der gar nicht mal so unsensiblen angehenden Stanford-Studentin:
"In so einer Welt leben wir doch schon längst."
Blohm hakt nochmal nach:
"Wir können vielleicht unserer Strafe entgehen, aber nicht unserer Schuld. Sie wird uns unser Leben lang unglücklich machen. Versau' dir nicht dein Karma."
"Wenn man die Wahrheit nicht beweisen kann, dann ist es auch nicht die Wahrheit"
Das ist eine zu schlichte Weltsicht, wie auch Blohm weiß, wenn sie wieder zu Sinnen kommt. Überhaupt wissen auch die Ermittler, dass die Welt anders funktioniert, als in Kinderbüchern und Moralfibeln: "Wenn man die Wahrheit nicht beweisen kann, dann ist es auch nicht die Wahrheit."
Subtiler sagt das Gleiche auch der Münchner Staranwalt Schellenberg, ein kluger Mann mit guten Kontakten in die bayerische Politik.
"Wenn du ein Problem hast, und Geld keine Rolle spielt, dann geh zum Schellenberg, der wird sicher lösen. Der hat schon vielen aus der Patsche geholfen. Und er macht mindestens zehn Fälle pro Jahr pro bono."
Löwe und Panther: "Deutung ist kein juristischer Begriff, Frau Blohm"
Das zentrale Gespräch zwischen Schellenberg und Blohm, den zwei weltanschaulichen Kontrahenten dieses Films ist der eigentliche Höhepunkt dieses Films und ein Fest schauspielerischen Könnens.
Blohm und Schellenberg die sich nicht fassen können, treffen sich zu einem Austausch auf neutralem Grund, in irgendeiner Bar in München. Sie trinkt einen Rotwein, er einen Cocktail. Sie belauern sich. Wie ein Löwe und ein Panther. Auf Augenhöhe, zwei Gegner, voller Respekt, Wahlverwandte und feindseliger Sympathie wider Willen füreinander.
Blohm fragt: "Haben sie kein Problem damit, wenn ihr Mandant unschuldig ist? Und der wahre Täter davon kommt?"
"Das kommt darauf an."
"Kommt drauf an?"
"Ich meine: Wenn ein Mandant tatsächlich ein falsches Geständnis ablegt, was soll ich da tun? Woher soll ich das wissen? Wie beurteilen? Wie verhindern? Ich hätte ein Problem, wenn mein Mandant unschuldig ist, ihm aber keiner glaubt."
Als Blohm ausführt, für sie "deute" viel auf die Tochter der Assauers hin, antwortet er kühl: "Deutung ist kein juristischer Begriff, Frau Blohm"
Gerechtigkeit ist kein Naturgesetz
Dann erklärt der mephistophelische Anwalt seine Weltsicht:
"Wissen Sie was Frau Blohm: Nehmen wir mal an, Sie hätten recht mit Ihrem Verdacht und das Ganze würde auffliegen – dann wäre das Leben einer jungen Frau ruiniert, weil sie wahrscheinlich ins Gefängnis müsste. So! Aber wem nützt das? Die jungen Leute kommen wieder raus, entsozialisiert, haben einen psychischen Knacks, finden nie wieder zurück. Läuterung? Besserung? Soll vorkommen – aber die Regel ist das nicht. Abschrecken konnten Gefängnisse eh noch nie und Affekttaten verhindern erst recht nicht. Also bleibt meist nur das Stigma der Öffentlichkeit übrig. Oder?"
"Aber was ist dann mit Strafe?"
"Sie meinen Rache?" -
"Nein, ich meine Gerechtigkeit."
Und wieder Schellenberg:
"Gerechtigkeit ist doch ein Gefühl, Gerechtigkeit ist ein Konstrukt, eine Idee. Kein Naturgesetz.
Also was würde passieren: Ein Unschuldiger gesteht freiwillig und bekommt dafür, was was ihm wichtiger ist, als ein paar Jahre seiner Freiheit. Die Opfer hätten ihren Schuldigen; dem Gerechtigkeitsempfinden der Gesellschaft wäre Genüge getan, also alle haben was sie wollen. Wen juckt da noch die objektive Wahrheit?"
Nietzsche gegen Kant
Schellenberg hat gute Argumente für sich. Wo Blohm mit Immanuel Kant und dem objektiven Sittengesetz argumentiert, antwortet Schellenberg ihr mit Friedrich Nietzsches Argument der Lebensdienlichkeit der Wahrheit:
"Vor dem Gesetz sind wir doch alle gleich."
"Das sind wir nicht, das wissen wir beide. Ärmere Schichten werden meist härter bestraft, als die Oberschicht. Aber was sie da meinen das erinnert mich eher an... an die Bibel: einer trage des anderen Last."
Anderenfalls "würden Sie die arme Familie auch noch um ihr Geld bringen."
Das ist der entscheidende Punkt: Es ist eben nicht zynisch, was Schellenberg tut, indem er Geständnisse arrangiert, sondern es ist realistisch. Es ist der Realismus, den "wir", den unsere Gesellschaft auf der politischen Ebene wie auf der privaten langsam wieder lernen muss. Ein Realismus, der seine Illusionen über die menschliche Natur und vor allem über die gesellschaftliche Natur abgelegt hat.
Schellenberg hat eben schon das Verlangen, sich Blohm zu erklären, denn er achtet sie. Blohm meint nicht alleine Gerechtigkeit. Sie meint, wie Schellenberg zu Recht vermutet hat, Rache, die Genugtuung der Gemeinschaft der Unschuldigen.
Einer trage des Anderen Last, aber nur die Reichen die der Armen. Und böse Anwälte sollen bestraft werden.
Der Bruch mit der Moralisierung
Das Wunderbare an diesem Krimi war, dass er die Moralisierung, die dem Fernsehkriminalfilm innewohnt, immer wieder bricht, und immer wieder zeigt, dass man alles, auch noch den größten Wert, von mindestens zwei Seiten aus betrachten kann.
Oberflächlich nach den Üblichkeiten des Fernsehkrimis betrachtetet, ist die von Tobias Moretti wunderbar sardonisch gespielte Figur – hier erinnerte er an seinen Auftritt als Ferdinand Marian in Oskar Roehers konsequent unterschätztem "Jud Süß" – des Schellenberg die, die am sichersten vom Handlungsverlauf bestraft werden muss.
Hier kommt es einmal, endlich anders. Dass das ausgerechnet der Fernsehkritik-Onkel der Zeit [2] nicht versteht, verwundert kaum. Vulgärmarxistisch fordert er "zumindest für die 90 Minuten seiner Spielzeit etwas an diesen Verhältnissen zu ändern, die er sich ausgedacht hat" und schwadroniert er über "die schuldige, also moralisch schon verderbte" Diplomatentochter, deren Schuld im Film übrigens nie bewiesen, nur nahegelegt wird, anstatt zu begreifen, dass sie vielleicht gerade juristisch schuldig, aber moralisch mit mildernden Umständen zu betrachten ist.
Der richtige Marxist Bertold Brecht wusste es besser: Den falschen Trost müsse moderner Realismus vermeiden.
Nietzsche siegt über Kant: Was ist Trost für den Einzelnen gegen den Trost eines ganzen Dorfes?
Die von Liliane Amuat auffällig konzentriert gespielte Frau des falschen Täters hat einen schlagendes Argument für ihr Schweigen zur Wahrheit: "Dann würde ja alles umsonst gewesen sein."
Da kann auch Frau Blohm nichts mehr machen.
Und der unschuldig einsitzende Afrikaner Leon erklärt ihr ihr Luxusproblem:
"Was wissen Sie von Gerechtigkeit? Wäre das Leben gerecht, würde meine Familie nicht in Armut leben."
So aber hat er den Tod einer Frau auf sich genommen und die Schuld, dass ein Triebtäter frei herumläuft. Denn was ist der Trost für einen Einzelnen gegen den Trost eines ganzen Dorfes? Auch Leon ist die Familie und die Heimat näher als die abstrakte Tugend, die konkrete Gerechtigkeit der Tat näher als die abstrakte Gerechtigkeit der regelbasierten Ordnung.Nietzsche siegt über Kant.
Der Film stellt das falsche und bequeme Verlangen der Menschen, immer und überall Gerechtigkeit herzustellen, infrage. Ja, ein Mörder läuft frei herum. Aber was ist das gegen die ganzen anderen Opfer, und gegen die Menschen seiner Familie und seines Dorfes, denen der Afrikaner dadurch helfen kann, dass er seine Ehre opfert?
Alles hängt mit allem zusammen, aber dieser Film hat den Mut, die Dinge so zu zeigen, wie sie sind. Und unsere Unzufriedenheit mit der Realität stehenzulassen.
"Gedenkt unserer mit Nachsicht"
Schellenberg möchte man weiter sehen. In zukünftigen Folgen. Und die Chancen scheinen gut, dass wir es auch können. Wenn die Macher klug sind, wenn vielleicht Christan Bach seine Geschichte weiter erzählen darf, dann wird er auch nicht so schnell und schlicht zur Strecke gebracht werden wie ein altes Wild.
Dann wird er vielleicht selbst ein Opfer werden und die andere Seite der Gerechtigkeit erfahren. Oder, besser noch, Blohm wird seine Hilfe brauchen, und er wird ihr helfen.
Für seine Sünden bezahlen kann er immer noch. Oder auch nicht.
"Ihr aber, wenn es so weit sein wird/ Dass der Mensch dem Menschen ein Helfer ist/ Gedenkt unserer/ Mit Nachsicht."
URL dieses Artikels: https://www.heise.de/-11214196
Links in diesem Artikel: [1] https://www.ardmediathek.de/tv-programm/6981e9cbb88a5fa381d3a8ee [2] https://www.zeit.de/feuilleton/film/2026-03/polizeiruf-110-muenchen-reichtum-verbrechen-resignation [3] https://www.deutschelyrik.de/an-die-nachgeborenen.html
95 Prozent zweckentfremdet: Wohin das "Sondervermögen" verschwunden ist
Von Marcel Kunzmann — 17. März 2026 um 14:00
Der größte Teil des schuldenfinanzierten "Sondervermögens" wurde zum Stopfen von Haushaltslöchern verwandt
Das Sondervermögen für Klima und Infrastruktur wurde laut Forschern größtenteils zweckentfremdet. Die Schulden-Milliarden flossen vor allem in den Haushalt.
Rund ein Jahr nach der Verabschiedung des 500-Milliarden-Euro-Sondervermögens für Infrastruktur und Klimaneutralität (SVIK) durch den Bundestag kommen zwei renommierte Wirtschaftsforschungsinstitute zu einem ähnlichen Befund: Die Mittel seien im Jahr 2025 überwiegend nicht für zusätzliche Investitionen in Infrastruktur und Klimaschutz verwendet worden.
Das Münchner ifo-Institut beziffert [1] den Anteil der neu aufgenommenen Schulden, die nicht in zusätzliche Infrastrukturinvestitionen geflossen sind, auf 95 Prozent. Das Institut der deutschen Wirtschaft Köln (IW) kommt auf [2] 86 Prozent zweckentfremdeter Mittel.
"Wir haben festgestellt, dass die Politik die schuldenfinanzierten Mittel nahezu vollständig für andere Zwecke, also zum Stopfen von Haushaltslöchern, genutzt hat. Das ist ein großes Problem", sagte ifo-Präsident Clemens Fuest. Die zusätzlich aufgenommenen Schulden hätten für Investitionen eingesetzt werden sollen, die das Wirtschaftswachstum langfristig stützen.
23 Milliarden Euro Lücke zwischen Schulden und Investitionen
Laut ifo-Analyse wurde die Schuldenaufnahme im Rahmen des SVIK im Jahr 2025 um 24,3 Milliarden Euro erhöht. Die tatsächlichen Investitionen des Bundes lagen jedoch nur um 1,3 Milliarden Euro über dem Niveau von 2024 – woraus sich eine Lücke von 23 Milliarden Euro ergibt, die nicht in zusätzliche Investitionen geflossen sind.
Die Ursache dafür liegt laut ifo-Forscherin Emilie Höslinger in der Umschichtung von Haushaltsmitteln: "Es kam zu Verschiebungen einzelner Posten vom Kernhaushalt in das kreditfinanzierte SVIK. Dazu gehören insbesondere Zuschüsse im Verkehrsbereich, weshalb im Kernhaushalt weniger investiert wurde als in den Vorjahren." Ein großer Teil der Investitionen im Sondervermögen sei deshalb nicht als zusätzlich zu werten.
Das Argument der Bundesregierung, dass es wegen langwieriger Gesetzgebungsverfahren oder realwirtschaftlicher Engpässe zu einem verzögerten Abfluss der Mittel gekommen sei, lässt das ifo-Institut nicht gelten: In diesem Fall hätten auch die Schulden nicht in diesem Ausmaß ansteigen dürfen.
"Verschiebebahnhof" und struktureller Geburtsfehler
Das IW beziffert die tatsächlichen Investitionsausgaben des Bundes 2025 – einschließlich des Sondervermögens und bereinigt um finanzielle Transaktionen – auf rund 71 Milliarden Euro. Das entspreche einem nominalen Anstieg von lediglich zwei Milliarden Euro gegenüber 2024, "gerade genug, um die Inflation auszugleichen", so das Institut.
Weitere zwölf Milliarden Euro aus dem SVIK hätten Ausgaben ersetzt, die zuvor aus dem regulären Haushalt finanziert worden seien.
IW-Forscher Tobias Hentze sprach in diesem Zusammenhang von einem "Verschiebebahnhof": So würden etwa "Sofort-Transformationskosten" für Krankenhäuser als Investitionen aus dem Sondervermögen verbucht, obwohl diese Mittel laufende Betriebskosten deckten. Geplant hatte der Bund, 19 Milliarden Euro aus dem SVIK auszugeben. "Nur drei von vier geplanten Euro flossen also tatsächlich ab", stellte das IW fest.
Hinzu kommt ein strukturelles Problem: Um auf das SVIK zugreifen zu dürfen, muss der Bund mindestens zehn Prozent seiner regulären Ausgaben in Investitionen stecken. In der Planung habe er diese Schwelle gerade so erreicht – tatsächlich aber habe die Quote nur bei 8,7 Prozent gelegen. "Konsequenzen hat das nicht: Die Vorgabe bezieht sich nur auf die geplanten, nicht auf die tatsächlichen Ausgaben", kritisierte das IW. "Damit fehlt ein wirksamer Kontrollmechanismus – ein struktureller Geburtsfehler."
"Union und SPD hatten die Chance, den Investitionsstau aufzulösen", sagte IW-Forscher Hentze. "Sie haben sie bislang nicht genutzt."
Forderungen für 2026
Beide Institute fordern von der Bundesregierung, die Mittel im laufenden Jahr konsequenter für den vorgesehenen Zweck einzusetzen. Das IW verlangt, die Ausgaben strikt an Infrastruktur und Klimaneutralität auszurichten und dafür auch schnellere Verwaltungsverfahren zu schaffen.
ifo-Experte Max Lay betonte: "Die Bundesregierung hat in Zukunft die Möglichkeit, die Quote der Zweckentfremdung zu senken. Dazu müssten vor allem die Investitionsausgaben im Kernhaushalt erhöht werden, sonst kann man auch weiterhin nicht von zusätzlichen Investitionen sprechen."
Das SVIK – das trotz seiner Bezeichnung als "Sondervermögen" tatsächlich kreditfinanzierte Schulden darstellt – wurde am 18. März 2025 noch vom alten Bundestag beschlossen, obwohl der neu gewählte Bundestag bereits feststand. Die erforderliche Zweidrittelmehrheit kam zustande, weil neben Union und SPD auch die Grünen zustimmten.
URL dieses Artikels: https://www.heise.de/-11213818
Links in diesem Artikel: [1] https://www.ifo.de/pressemitteilung/2026-03-17/regierung-95-prozent-neue-schulden-infrastruktur-2025-zweckentfremdet [2] https://www.iwkoeln.de/presse/iw-nachrichten/tobias-hentze-86-prozent-des-sondervermoegens-zweckentfremdet.html
Das MacBook Neo schickt sich an, den PC-Markt aufzuwirbeln und signalisiert auch einen Umbruch bei Apple. Wir ordnen ein.
Wenig hat 2026 für so viel Aufregung in der IT-Welt gesorgt wie das MacBook Neo. Dabei ist es gar kein futuristisch anmutendes Gerät mit großen Visionen, sondern ein simples Klapp-Notebook. Und doch scheint auf dem PC-Markt seitdem vieles anders: Zum ersten Mal wildert ein neues MacBook im Preissegment knapp unter 700 Euro und die großen Konkurrenten wirken denkbar schlecht vorbereitet – zumal alle genau jetzt von einer massiven Speicherkrise überrollt werden.
In Episode 117 besprechen Malte Kirchner und Leo Becker, an welchen Stellen Apple beim Neo gerade nicht gespart hat und was den MacBook-Neuling attraktiv macht – für Umsteiger wie altgediente Mac-Nutzer. Wir sprechen über ungläubige Reaktionen ebenso wie über Reparierbarkeit und Apples großen Komponenten-Baukasten, aus dem sich neue Produkte zusammenwürfeln lassen. Uns beschäftigt außerdem, was das Neo für Apples andere Produktreihen bedeutet, besonders das iPad. Zudem fragen wir uns, ob Apple mit dem Neo plötzlich wieder eine spielerische Seite wiederentdeckt hat – und das einen großen Umbruch andeutet.
Apple-Themen – immer ausführlich
Der Apple-Podcast von Mac & i erscheint mit dem Moderatoren-Duo Malte Kirchner und Leo Becker im Zweiwochenrhythmus und lässt sich per RSS-Feed (Audio [2]) mit jeder Podcast-App der Wahl abonnieren – von Apple Podcasts über Overcast bis Pocket Casts.
Design gleichbleibend: Nur „Spec Bump“ für die AirPods Max 2
Von Heise — 17. März 2026 um 14:01
AirPods Max 2: Auf den ersten Blick kein Unterschied.
(Bild: Apple)
Wenn Apple größere technische Veränderungen vornimmt, wird oft auch am Look geschraubt. Bei den neuen Top-Over-Ears ist das nicht der Fall.
So mancher Freund von Apples noblen AirPods Max [1] dürfte verdutzt geschaut haben, als Apple gestern außer der Reihe und praktisch ohne Vorabgerüchte die AirPods Max 2 [2] vorstellte. Und mancher, der sich im Herbst 2024 die USB-C-Variante gekauft [3] hat, wird sich sogar ärgern, nicht gewartet zu haben. Denn während die USB-C-Modelle bis auf besagten Port (sowie die Möglichkeit, Lossless Audio via USB-C zu übertragen [4]) keine weiteren Neuerungen mitbrachten, sind die AirPods Max 2 eine Totalrenovierung im Inneren. Das wirkt umso merkwürdiger, weil das Außendesign gleich geblieben ist. Selbst an den verfügbaren Einfärbungen hat sich nichts geändert, sodass man die AirPods Max 2 von den AirPods Max USB-C quasi nicht unterscheiden kann.
Lange erwarteter H2-Chip, aber keine neuen Treiber
Warum Apple diese Kombination wählte – altes Design mit neuem Innenleben – ist nicht bekannt. Die Situation erinnert ein wenig an das neue Studio Display XDR [5], das ebenfalls den alten Look behalten hat, aber innen samt Panel vollständig neu ist. Klar scheint bereits zu sein, dass bald viele AirPods Max USB-C im Gebrauchtwarenhandel landen. Die Neuerungen bei den AirPods Max 2 sind durchaus spannend. Immerhin hat Apple den (hohen) Preis beibehalten und nicht erhöht.
Die AirPods Max 2 haben endlich den lange erwarteten H2-Chip, den man in AirPods-Pro-Stöpseln bereits seit der zweiten Generation (von 2022) verwendet. Umgesetzt wird dadurch unter anderem eine bessere Geräuschunterdrückung (ANC), Features wie Konversationserkennung und Adaptive Audio, Live-Übersetzung und Sprachisolation, plus personalisierte Lautstärke. An der eingebauten akustischen Hardware hat Apple offenbar nicht gedreht, sowohl die Treiber als auch die Basisarchitektur ändern sich nicht – mit Ausnahme eines neuen Verstärkers. Dafür kann man mit der digitalen Krone nun Videos oder Fotos auslösen, wenn das Gerät mit einem iPhone oder iPad gekoppelt ist.
Die AirPods Max 2 hätten früher kommen können
Die AirPods Max 2 lassen einen dann auch etwas ratlos zurück. Die Geräte, die jetzt erscheinen, hätte Apple nämlich problemlos bereits im Herbst 2024 auf den Markt bringen können. Doch zum damaligen Zeitpunkt kam eben nur USB-C und kein neuer Audiochip, wobei ersteres auch auf Druck der EU-Kommission [6] und ihrer USB-C-Vorgaben geschehen sein dürfte.
Die AirPods Max 2 können ab dem 25. März vorbestellt werden und erscheinen Anfang April. Apple verlangt weiterhin 579 Euro – 20 Euro weniger als der Bildungstarif für das MacBook Neo [7] übrigens.
URL dieses Artikels: https://www.heise.de/-11214130
Bis zu 10.000 mAh: Zens mit dünnen Solid-State-Powerbanks für iPhone & Co.
Von Heise — 17. März 2026 um 12:55
Neue Zens-Akkus: Für iPhone Air leider nicht geeignet.
(Bild: Zens)
Zens hat zwei neue externe Batterien für Smartphones im Programm, die dank Semi-Solid-State-Technik weniger auftragen sollen.
Neues von Zens: Der niederländische Spezialist für Qi- und MagSafe-Ladestationen erweitert sein Geschäft mit Powerbanks. Neben gewöhnlichen Varianten mit üblichem Lithium-Ionen-Akku gibt es künftig auch sogenannte Semi-Solid-State-Batterien. Dabei handelt es sich um eine veränderte Batteriearchitektur, die unter anderem weniger anfällig für Brände (Thermal Runaway [1]), physische Schocks/Stöße und Temperaturwechsel sein soll. Auch die Gesamtakkulebensdauer soll sich erhöhen. Das Gesamtgewicht und die Zellgröße sinken zudem.
Kombi gegen Stöße und Temperaturschwankungen
Die Technik kombiniert Verfahren von klassischen Lithium-Ionen-Batterien mit einem flüssigen Elektrolytmaterial mit einer vollständig festen Batteriechemie. Dabei kommt ein Hybridmaterial aus festem und flüssigem Zustand heraus, das die Vorteile der Solid-State-Technik (insbesondere deren Stabilität gegenüber flüssigen Elektrolytmaterialien) mit der kostengünstigen Produktion herkömmlicher Akkus kombinieren soll. Was das in der Praxis bedeutet, müssen allerdings erst Tests zeigen.
Zens verspricht, dass seine Semi-Solid-State-Powerbanks mehr Ladevorgänge schaffen sollen als Lithium-Ionen-Zellen, macht allerdings keine genaueren Angaben. Es wird zwei Varianten [2] geben, die sich aktuell vorbestellen lassen: Die Ladegeschwindigkeit liegt bei maximal 25 Watt (iPhone 16 oder neuer), bei älteren iPhones und kompatiblen Android-Geräten bei 15 Watt.
Zwei Varianten mit 5000 und 10.000 mAh
Die 5000-mAh-Variante ist 8 mm dünn (etwas dicker als Apples MagSafe-Batterie für das iPhone Air [3], die aber weniger mAh hat), die 10.000-mAh-Variante 14 mm. Es lassen sich bis zu zwei Geräte gleichzeitig laden. Power-Passthrough erlaubt es zudem, erst den Akku und dann das iPhone (beziehungsweise umgekehrt) aufzuladen.
Es blieb zunächst unklar, ob der Akku mit dem iPhone Air arbeitet, das wegen der Kameraplattform eine spezielle Anordnung des MagSafe-Bereichs hat. Das iPhone 17 wird in allen Varianten unterstützt, ebenso wie alle anderen iPhones ab iPhone 12 (siehe oben). Die Preise liegen bei 60 respektive 80 Euro. Lieferbeginn soll Ende März (5000 mAh) beziehungsweise Anfang April (10.000 mAh) sein. Das Gewicht beider Modelle bleibt unklar – Zens nennt hier nur den Wert von 122 g, das gilt aber wohl nur für die 5000-mAh-Variante.
URL dieses Artikels: https://www.heise.de/-11212486
Links in diesem Artikel: [1] https://www.heise.de/ratgeber/Warum-ein-Akku-brennt-und-wie-Sie-es-verhindern-koennen-9814045.html [2] https://zens.tech/de/products/semi-solid-state-powerbank [3] https://www.heise.de/news/iPhone-Air-bekommt-externen-Akku-speziell-fuer-dieses-Modell-10639409.html [4] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html [5] https://www.heise.de/mac-and-i [6] mailto:bsc@heise.de
DoS-Attacken auf IBM SPSS Collaboration and Deployment Services möglich
Von Heise — 17. März 2026 um 15:02
(Bild: Tatiana Popova/Shutterstock.com)
IBMs Analyse- und Automationssoftware SPSS Collaboration and Deployment Services ist verwundbar. Sicherheitspatches sind verfügbar.
Angreifer können Systeme mit IBM SPSS Collaboration and Deployment Services attackieren und unter anderem DoS-Zustände auslösen. Ansatzpunkte sind mehrere Sicherheitslücken in diversen Komponenten, die die Analyse- und Automationssoftware nutzt.
Sicherheitsupdate installieren
Wie aus einer Warnmeldung hervorgeht [1], können Angreifer insgesamt neun Schwachstellen in js-yaml, minimatch und React Router ausnutzen. Davon sind fünf Lücken mit dem Bedrohungsgrad „hoch“ eingestuft. Daran können Angreifer etwa für DoS- (CVE-2026-26996) und XSS-Attacken (CVE-2026-21884) ansetzen. Bislang gibt es keine Berichte, dass die Lücken bereits ausgenutzt werden.
Admins sollten sicherstellen, dass die gegen die geschilderten Attacken gerüstete Version 9.0.0.0-IM-ScaDS-REPOSITORYSERVER-PSIRT-IF002 installiert ist.
URL dieses Artikels: https://www.heise.de/-11214186
Links in diesem Artikel: [1] https://www.ibm.com/support/pages/node/7266375 [2] https://pro.heise.de/security/?LPID=39555_HS1L0001_27416_999_0&wt_mc=disp.fd.security-pro.security_pro24.disp.disp.disp [3] mailto:des@heise.de
IT-Forscher haben in sogenannten Sextortion-Betrugsmails echte Passwörter gefunden. Die stammen aus Wegwerf-E-Mail-Diensten.
Bei der Betrugsmasche mit dem Namen „Sextortion“ versuchen Kriminelle, Opfer mit angeblichen Aufnahmen von der Rechner- oder Smartphone-Kamera zu Geldzahlung zu bewegen. Bei diesen Erpressungs-E-Mails handelt es sich in aller Regel um Betrug, die Täter haben sich an keiner Stelle unbefugten Zugang zu den IT-Systemen der Opfer verschafft. Um jedoch den Eindruck davon zu erwecken, packen die kriminellen Drahtzieher nun echte Passwörter in die Betrugsmails.
Das berichten IT-Forscher von Malwarebytes in einem aktuellen Blog-Beitrag [1]. Die aktuellen betrügerischen E-Mails landen mit Betreffzeilen wie „You pervert, I recorded you!“ in den Posteingängen potenzieller Opfer. Im Mailtext behaupten die Täter, das Gerät der Opfer mit einem „Drive-by-Exploit“ infiziert zu haben, wodurch sie vollen Zugriff darauf erlangt und die Mailempfänger beim Videomaterial beim „Mastrubieren“ durch die Kamera aufgenommen hätten. Um die Glaubwürdigkeit zu erhöhen, nennen die Angreifer ein Passwort in der E-Mail, das es tatsächlich gibt. Im folgenden Text der Mail versuchen die Angreifer, weiter Druck aufzubauen und Opfer dazu zu bringen, ihnen Kryptogeld zu überweisen. Nachdem das geschehen sei, würden sie alle Spuren ihrer Malware entfernen – die vermeintlich inkriminierenden Materialien finden keine weitere Erwähnung.
Die IT-Forscher haben die Adresse eines betrügerischen Absenders in mehreren Mails gefunden, die an Menschen gerichtet waren, die einen Anbieter von Wegwerf-E-Mail-Adressen nutzen, im konkreten Fall FakeMailGenerator. Diese kostenlosen Angebote erlauben das Anlegen einer temporären E-Mail-Adresse und anschließend das Einsehen von Mails dorthin. Das ermöglicht das Anmelden bei Diensten, ohne die echte E-Mail-Adresse zu verwenden – etwa als Spam-Schutzmaßnahme. Von diesen Konten aus lassen sich üblicherweise keine E-Mails versenden, sondern nur empfangen. Der Posteingang gehört keiner einzelnen Person, sondern jeder kann nach Angabe der E-Mail-Adresse jedes beliebige temporäre Mail-Konto einsehen.
Passwörter aus Wegwerf-Mailkonten
Malwarebytes nimmt an, dass die Betrüger diese öffentlichen Posteingänge nach Passwörtern durchsuchen und diese in ihren Sextortion-Mails einsetzen. Für Nutzer solcher Wegwerf-Mail-Adress-Angebote sollte das als Warnung dienen. Der Posteingang könnte öffentlich zugreifbar sein, in Suchergebnissen auftauchen. Solche Angebote sollte niemand für etwas Vertrauliches einsetzen.
Die Täter hinter solchen Sextortion-Betrugsmails waren Mitte vergangenen Jahres stark [2] von der Inflation betroffen. Die Zahlungsforderungen sind dort deutlich angestiegen. Im April 2025 betrugen sie noch 1200 US-Dollar, im Mai dann 1450 US-Dollar, um dann im Juni auf 1650 US-Dollar zu klettern. In der jetzt beobachteten Spam-Welle betrug die Forderung lediglich 800 US-Dollar.
URL dieses Artikels: https://www.heise.de/-11214086
Links in diesem Artikel: [1] https://www.malwarebytes.com/blog/news/2026/03/sextortion-i-recorded-you-emails-reuse-passwords-found-in-disposable-inboxes [2] https://www.heise.de/news/Sextortion-Inflationsgebeutelte-Betrueger-erhoehen-Forderungen-10460953.html [3] https://pro.heise.de/security/?LPID=39555_HS1L0001_27416_999_0&wt_mc=disp.fd.security-pro.security_pro24.disp.disp.disp [4] mailto:dmk@heise.de
Vor allem, weil OpenClaw andere Anwendungen und Systemdienste steuern kann, ergeben sich immer wieder neue Sicherheitsrisiken.
Wer mit OpenClaw arbeitet, sollte der Computer- und Datensicherheit zuliebe regelmäßig nach neuen Versionen Ausschau halten und sie umgehend installieren. Die Entwickler veröffentlichen pro Woche mehrere Versionen des KI-Agenten, die in der Regel auch Sicherheitsupdates enthalten – und das wird sich in absehbarer Zukunft nicht ändern.
Um sein volles Potenzial entfalten zu können, muss OpenClaw [1] mit weitreichenden Systemrechten laufen. Dann kann er etwa über einen Messenger wie Signal instruiert E-Mails verschicken, Bilder erzeugen und sogar Software installieren. Das ist super praktisch, aber auch super gefährlich. Das Zusammenspiel verschiedener Anwendungen ergibt nämlich immer wieder neue Sicherheitsrisiken.
Volles Gefahrenspektrum
Zuletzt etwa im Zusammenspiel mit Telegram, wo einer Warnmeldung zufolge [2] bestimmte Anfragen eine hohe Ressourcenauslastung auslösen können. Weil Anhänge im Kontext von iMessage [3] nicht ausreichend geprüft werden, können Angreifer eigene Befehle ausführen.
Überdies stoßen Sicherheitsforscher immer wieder auf Schwachstellen im Code von OpenClaw. Darunter sind regelmäßig „kritische“ Lücken, teilweise sogar mit dem höchstmöglichen CVSS Score 10 von 10 [4]. In diesem Fall können Angreifer als Admins auf Instanzen zugreifen. In anderen Fällen können Angreifer sogar Schadcode ausführen. Danach gelten PCs in der Regel als vollständig kompromittiert.
Holzauge sei wachsam
Weil alle paar Tage neue Sicherheitsupdates erscheinen, können wir nicht alle melden, ohne zum reinen OpenClaw-Ticker zu verkommen. Wer den KI-Agenten also nutzt, sollte regelmäßig, wenn nicht sogar täglich, nach Aktualisierungen Ausschau halten.
Wenn Spiele sich selbst erschaffen: Neues Buch angekündigt
Von Heise — 17. März 2026 um 12:20
(Bild: Cover: Bloomsbury Sigma, Hintergrund: KI, Nano Banana)
Wenn Spiele sich selbst erschaffen, ist das nicht unbedingt KI. Vor allem in älteren Games entsteht die Magie durch die natürliche Intelligenz der Entwickler.
Wer schon einmal staunend durch die endlosen Landschaften von Minecraft gewandert ist, sich in den absurd detaillierten Geschichten von „Dwarf Fortress“ verloren oder in einem Roguelike jedes Mal ein völlig neues Level vorgefunden hat, der hat – oft ohne es zu wissen – prozedurale Generierung erlebt. Keine KI im heutigen Sinne, kein neuronales Netz, kein Large Language Model. Sondern clevere Algorithmen, die nach Regeln und mit kontrolliertem Zufall Spielinhalte erschaffen: Welten, Dungeons, Kreaturen, ganze Erzählungen.
(Bild: Bloomsbury Sigma)
Genau diesem Thema widmet sich das englischsprachige Werk „Next Level: Making Games That Make Themselves“ von Mike Cook – es erscheint am 7. Mai 2026 bei Bloomsbury Sigma und ist bereits jetzt für ca. 25 Euro vorbestellbar.
Generativ ≠ generative KI
Der Begriff „generativ“ hat durch den KI-Boom der letzten Jahre eine neue Konnotation bekommen. Doch generative Systeme in Spielen sind sehr viel älter – und in vielerlei Hinsicht faszinierender, als man zunächst denkt. Prozedurale Generierung reicht zurück bis zu genreprägenden Titeln der 1980er-Jahre und bildet bis heute das Rückgrat einiger der erfolgreichsten Spiele überhaupt. Hier geht es nicht um Prompts und Diffusion-Modelle, sondern um handgeschriebene Algorithmen, geschickte Regelsysteme und die Kunst, dem Computer beizubringen, kreativ zu wirken – mit Mathematik, Logik und einer gehörigen Portion Designintuition.
Das Buch entmystifiziert diese Techniken: Wie entstehen unendliche Landschaften? Wie generiert ein Algorithmus ein Level, das sich fair und spielbar anfühlt? Wie erzeugen prozedurale Systeme Geschichten, die überraschen, ohne ins Absurde abzugleiten? Cook nimmt die Leserinnen und Leser mit auf eine Tour durch die Geschichte und Gegenwart dieser Verfahren – und erklärt verständlich, was unter der Haube passiert.
Der Autor: Forscher, Gamedesigner, Maker
(Bild: Dr. Michael Cook)
Dr. Michael Cook ist KI-Forscher und Gamedesigner [1] am King's College London, wo er als Deputy Head der Human-Centred Computing Group arbeitet. Er ist der Kopf hinter „ANGELINA“, einem Forschungsprojekt zu KI-gestütztem Gamedesign, und Gründer von „PROCJAM“, einer Community rund um prozedurale Generierung. Eine lange Liste von wissenschaftlichen Veröffentlichungen [2] zeugt von dieser Arbeit. Cook bewegt sich seit Jahren an der Schnittstelle von Forschung, Indie-Gamedev und Maker-Kultur – und bringt genau diese Perspektive ins Buch ein. Auf Bluesky schreibt er über das Buch: „It's about how it works, the games that use it, and the art and magic behind it.“
Für wen ist dieses Buch?
Für alle der englischen Sprache Mächtigen, die sich für die kreative Seite von Spieleentwicklung begeistern – ob als Maker, Hobbyentwicklerin, Informatikstudent oder einfach als neugieriger Mensch, der wissen will, warum die Höhlen in Minecraft in jeder Welt anders aussehen. Das Buch richtet sich ausdrücklich nicht nur an ein Fachpublikum: Mit 288 Seiten verspricht es eine zugängliche, erzählerische Reise durch die Welt der prozeduralen Generierung, die zum Staunen und zum Selbermachen einlädt.
Java 26 führt HTTP/3 ein und verzichtet endgültig auf die Applet-API
Von Heise — 17. März 2026 um 15:00
(Bild: Natalia Hanin / Shutterstock.com)
Das aktuelle OpenJDK 26 ist strategisch wichtig und bringt nicht nur spannende Neuerungen, sondern beseitigt auch Altlasten wie die veraltete Applet-API.
Im Herbst 2025 erschien mit dem OpenJDK 25 die aktuelle Version, für die viele Hersteller einen Long-Term-Support (LTS) anbieten. Viele Unternehmen nutzen solche Releases als Stabilitätsanker für Migrationen und langfristige Planung. Java 26 ist dagegen wieder ein reguläres Halbjahres-Release und damit ein Schritt in einer kontinuierlichen Evolution der Plattform: Sprache, Runtime und Standardbibliothek werden systematisch modernisiert, ohne die Stabilität und Abwärtskompatibilität zu gefährden, für die Java seit Jahrzehnten bekannt ist.
Ein kleines Release mit strategischer Bedeutung
Insgesamt enthält Java 26 zehn JEPs (JDK Enhancement Proposals). Ein Teil davon setzt bekannte Entwicklungen fort, etwa bei Pattern Matching, Structured Concurrency oder der Vector API. Andere Änderungen betreffen die Performance der JVM, neue Netzwerkprotokolle oder Verbesserungen im Security-Stack. Hinzu kommen einige Aufräumarbeiten im JDK, etwa die endgültige Entfernung der alten Applet-API.
Auch wenn Java 26 auf den ersten Blick unspektakulär wirkt, ist seine strategische Bedeutung nicht zu unterschätzen. Einige der Änderungen bereiten die Plattform auf größere Entwicklungen vor, die in den kommenden Jahren anstehen. Dazu gehören insbesondere Project Valhalla mit den Value Types, eine stärkere Integrität des Objektmodells unter dem Leitgedanken „Integrity by Default“ sowie die Optimierungen für moderne Hardware, KI- und Cloud-Workloads.
HTTP/3 Unterstützung im Java HTTP Client
Der in Java 11 eingeführte java.net.http.HttpClient hat sich in den vergangenen Jahren zum Standardwerkzeug für HTTP-Kommunikation in Java-Anwendungen entwickelt. Mit Java 26 unterstützt diese API nun auch HTTP/3 (JEP 517 [1]). HTTP/3 setzt nicht mehr auf TCP, sondern auf QUIC, einem UDP-basierten Transportprotokoll. Dadurch ergeben sich mehrere Vorteile gegenüber HTTP/1.1 und HTTP/2:
geringere Latenz beim Verbindungsaufbau,
bessere Performance bei Paketverlust,
kein Head-of-Line-Blocking zwischen parallelen Streams und
stabilere Verbindungen bei Netzwechsel, etwa bei mobilen Clients.
Gerade in Cloud-Umgebungen oder bei global verteilten Anwendungen kann HTTP/3 spürbare Vorteile bringen. Für Entwicklerinnen und Entwickler bleibt die Nutzung der API dagegen weitgehend unverändert. Die gewünschte HTTP-Version können sie einfach beim Erstellen des Clients angeben:
Lazy Constants: Initialisierung von Konstanten erst bei Bedarf
Mit JEP 526 [2] bringt Java 26 eine weitere Iteration der sogenannten Lazy Constants. Das Feature war bereits in Java 25 unter dem Namen Stable Values enthalten und erscheint nun als zweite Preview mit einer überarbeiteten API. Die Idee dahinter ist einfach: Konstanten sollen erst dann berechnet werden, wenn die Anwendung sie benötigt. Bisher erzeugt die JVM final-Felder im Rahmen der Klasseninitialisierung. Das ist effizient, wenn die Anwendung die Werte verwendet, kostet aber Zeit beim Start. In der Praxis können aufwendig zu erzeugende Objekte enthalten sein, die eine Anwendung möglicherweise nie oder erst viel später benötigt. Darum ist es sinnvoll, sie auch erst später zu initialisieren. Ein typisches Beispiel sind vorbereitete reguläre Ausdrücke oder Lookup-Strukturen:
Beim Laden der Klasse werden hier alle Patterns sofort kompiliert – unabhängig davon, ob sie später verwendet werden oder nicht. Eine solche Initialisierung selbst lazy umzusetzen, ist schwierig. Sie muss Thread-sicher sein und darf gleichzeitig möglichst wenig Synchronisations-Overhead erzeugen. Ein klassischer Ansatz wäre das sogenannte Double-Checked Locking:
Solche Konstrukte sind nicht nur fehleranfällig, sondern vor allem schwer lesbar und führen schnell zu subtilen Nebenläufigkeitsproblemen. Lazy Constants lösen dieses Problem direkt auf Plattformebene:
Die JVM übernimmt die Thread-sichere Initialisierung beim ersten Zugriff, sodass Entwicklerinnen und Entwickler keine eigenen Synchronisationsmechanismen implementieren müssen. Die JVM hat zudem die Möglichkeit, Optimierungen vorzunehmen. Das kann zudem in späteren Java-Releases zu Performanceverbesserungen führen.
Die aktuelle Preview bringt eine im Vergleich zum ersten Entwurf deutlich vereinfachte API. Niedrigstufige Methoden wie orElseSet() oder trySet() sind nicht mehr enthalten. Stattdessen konzentriert sich die API nun auf Fabrikmethoden, die den Inhalt über eine Berechnungsfunktion erzeugen. Zusätzlich soll der von StableValue zu LazyConstant geänderte Name den Zweck klarer beschreiben: einen konstanten Wert, der erst bei Bedarf erzeugt wird. Gerade in Cloud- und Microservice-Architekturen kann das Vorteile bringen. Anwendungen starten schneller, unnötige Objektallokationen werden vermieden und der Speicherbedarf in der frühen Laufphase einer Anwendung sinkt.
JVM-Optimierungen für moderne Workloads
Neben neuen APIs enthält Java 26 mehrere Verbesserungen in der Laufzeitumgebung. Sie zielen vor allem auf zwei typische Anforderungen moderner Anwendungen ab: hoher Durchsatz bei paralleler Last und schnelleres Startverhalten in Cloudumgebungen.
Mehr Durchsatz im G1 Garbage Collector
Der Garbage Collector (GC) G1 ist seit vielen Jahren der Standard-GC der JVM. Seine Stärke liegt in relativ stabilen Pausenzeiten bei gleichzeitig gutem Durchsatz. In Systemen mit vielen CPU-Kernen stieß G1 jedoch bislang an interne Skalierungsgrenzen, weil bestimmte Operationen stark synchronisiert waren. Mit JEP 522 [3] reduziert Java 26 gezielt diese Synchronisationspunkte. Dadurch entsteht weniger Lock Contention im Garbage Collector, und die Parallelisierung lässt sich besser nutzen. Besonders profitieren davon Anwendungen mit vielen Threads und hoher Objektallokation – etwa hoch parallele Backend-Systeme oder datenintensive Batch-Workloads.
Ein weiterer Schritt in Richtung schnellerer Starts ist JEP 516 [4]. Dahinter verbirgt sich ein Mechanismus, der es erlaubt, bestimmte Objekte bereits im Voraus zu erzeugen und wiederzuverwenden. Typische Kandidaten dafür sind:
Lookup-Tabellen,
Konfigurationsstrukturen,
Metadatenobjekte und
häufig verwendete String- oder Datenstrukturen.
Statt diese Strukturen bei jedem Start neu aufzubauen, können sie vorbereitet und beim Start direkt wiederverwendet werden. Das reduziert die Initialisierungsarbeit und verkürzt die Warm-up-Phase einer Anwendung. Ein wichtiger Unterschied zu früheren Ansätzen ist, dass dieses Ahead-of-Time Object Caching nun unabhängig vom verwendeten Garbage Collector funktioniert. Dadurch lässt sich die Optimierung mit unterschiedlichen GC-Konfigurationen kombinieren. Gerade in containerisierten Umgebungen kann das relevant sein. Anwendungen starten schneller, Auto-Scaling reagiert effizienter und der Ressourcenbedarf während der Startphase sinkt.
PEM Encodings im JDK
Mit JEP 524 [5] verbessert Java 26 in der zweiten Preview den Umgang mit kryptografischen Schlüsseln und Zertifikaten. Das JDK erhält eine native Unterstützung für PEM-kodierte kryptografische Objekte.
PEM („Privacy-Enhanced Mail“) ist ein textbasiertes Format zur Darstellung von Zertifikaten und Schlüsseln, das in vielen Bereichen zum Einsatz kommt, etwa für X.509-Zertifikate, Public und Private Keys oder Certificate Signing Requests. Eine typische PEM-Datei sieht folgendermaßen aus:
-----BEGIN PUBLIC KEY-----
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEi/kRGOL7wCPTN4KJ2ppeSt5UYB6u
cPjjuKDtFTXbguOIFDdZ65O/8HTUqS/sVzRF+dg7H3/tkQ/36KdtuADbwQ==
-----END PUBLIC KEY-----
Obwohl dieses Format im TLS- und Cloud-Umfeld weitverbreitet ist, war die direkte Unterstützung im JDK bislang begrenzt. Entwickler und Entwicklerinnen mussten häufig auf Drittbibliotheken zurückgreifen oder eigene Parser implementieren. Die neue API übernimmt zentrale Aufgaben wie das Einlesen von PEM-Daten, das Entfernen der Header und Footer sowie das Base64-Decoding. Dadurch lassen sich Zertifikate und Schlüssel direkt mit Bordmitteln des JDK verarbeiten. Gerade in aktuellen Deployment-Szenarien tauchen PEM-Dateien häufig auf, etwa in Kubernetes-Secrets, TLS-Konfigurationen, ACME-/Let’s-Encrypt-Integrationen oder mTLS-Set-ups zwischen Services. Die native Unterstützung reduziert Boilerplate-Code und verringert die Abhängigkeit von externen Security-Bibliotheken.
Aufräumarbeiten im JDK
Zur Evolution einer Plattform gehört nicht nur das Hinzufügen neuer Funktionen, sondern auch das konsequente Entfernen überholter Technologien und das Korrigieren von Fehlverhalten. Java 26 enthält zwei Änderungen, die auf den ersten Blick unspektakulär wirken, aber eine klare strategische Richtung zeigen.
Das JEP 504 entfernt die Applet-API [6] endgültig aus dem JDK. Applets waren in den 1990er-Jahren ein zentrales Versprechen der Java-Plattform: Java-Code sollte direkt im Browser laufen und so interaktive Webanwendungen ermöglichen. Diese Zeit ist längst vorbei. Moderne Browser unterstützen keine NPAPI-Plug-ins mehr, Sicherheitsanforderungen sind deutlich gestiegen und Webanwendungen basieren heute auf völlig anderen Architekturen – etwa JavaScript-Frameworks, REST-APIs oder Single-Page-Applications. Die Applet-API ist bereits seit mehreren Java-Versionen als „deprecated for removal“ markiert und verschwindet nun endgültig aus dem JDK. Für aktuelle Anwendungen hat diese Änderung praktisch keine Auswirkungen.
Deutlich weitreichender ist JEP 500 [7]: „Prepare to Make Final Mean Final“. In der Java-Sprache garantiert das Schlüsselwort final, dass ein Feld nach der Konstruktion nicht mehr verändert werden kann. In der Praxis ließ sich diese Einschränkung jedoch über Reflection oder Low-Level-APIs wie Unsafe umgehen. Viele Frameworks – insbesondere Serialisierungsbibliotheken – nutzten diese Möglichkeit, um Objekte ohne Aufruf des Konstruktors zu erzeugen oder Felder direkt zu manipulieren. Das Vorgehen kann jedoch wichtige Validierungsregeln (Invarianten) eines Objekts verletzen.
Als Beispiel dient folgende Java-Klasse mit Preconditions:
public class Adult {
private final Instant birthdate;
public Adult(Instant birthdate) {
this.birthdate = birthdate;
if (isYoungerThan18(birthdate)) {
throw new IllegalArgumentException("Not 18 yet");
}
}
}
Wird ein Objekt dieser Klasse beispielsweise per Reflection erzeugt, kann eine Anwendung birthdate setzen, ohne dass die Validierung im Konstruktor ausgeführt wird. Das Ergebnis ist ein Objekt in einem ungültigen Zustand. JEP 500 bereitet daher den Weg für ein strengeres Integritätsmodell. Ziel ist es, dass final künftig standardmäßig tatsächlich die Unveränderlichkeit garantiert. Unsichere Zugriffe auf solche Felder sollen eingeschränkt werden, während Übergangsmechanismen über JVM-Parameter weiterhin Kompatibilität mit bestehendem Code ermöglichen. Diese Entwicklung ist Teil eines größeren Trends unter dem Stichwort „Integrity by Default“. Die Plattform bewegt sich weg von einem Modell, in dem Frameworks beliebig tief in das Objektmodell eingreifen können, und hin zu einem Ansatz, der Invarianten stärker schützt und bei dem das Verhalten von Objekten verlässlicher bleibt.
Während die bisher beschriebenen JEPs hauptsächlich neue Themen umfassten, gibt es wie bei jedem JDK-Release einige langlaufende Preview- und Inkubator-Features. Dazu zählen die Primitive Types in Patterns (mittlerweile in der vierten Fassung), die Structured Concurrency (sechste Preview) und die Vector API (zum elften Mal als Inkubator-Feature).
Pattern Matching über primitive Typen
Seit Java 21 entwickelt sich Pattern Matching schrittweise zu einem zentralen Sprachkonzept. Ziel ist es, komplexe Typprüfungen und Fallunterscheidungen einfacher und sicherer auszudrücken. Gemeinsam mit Records und Sealed Classes lassen sich damit Strukturen ähnlich wie algebraische Datentypen modellieren, wodurch viele ungültige Zustände bereits auf Typebene ausgeschlossen werden können. Nach Type Patterns, Pattern Matching im switch, Record Patterns und Unnamed Patterns sind Primitive Type Patterns der nächste Schritt in der Entwicklung von Java hin zum datenorientierten Paradigma. Das Feature tauchte erstmals bereits in Java 23 auf und erscheint in Java 26 mit JEP 530 als vierte Preview [8]. Inhaltlich hat sich gegenüber dem letzten Release wenig geändert – das OpenJDK-Team sammelt weiterhin Feedback, bevor es die Funktion finalisiert.
Pattern Matching erlaubt es, Datenstrukturen mit einem Muster zu vergleichen und gleichzeitig Teile daraus zu extrahieren. Ein Pattern kombiniert dabei eine Bedingung („passt dieser Typ oder Wertebereich?“) mit Variablen, in die passende Werte gebunden werden. Während dieses Konzept bisher nur für Referenztypen galt, erweitert Java 26 es auf primitive Datentypen und erlaubt es, primitive und Referenztypen austauschbar im Pattern Matching-Kontext zu verwenden. Das folgende Beispiel zeigt, wie man ein int verlustfrei in einen byte konvertiert:
private static String checkByte(int value) {
if (value instanceof byte b) {
return "byte b = " + b;
} else {
return "kein byte: " + value;
}
}
System.out.println(checkByte(127)); // byte b = 127
System.out.println(checkByte(128)); // kein byte: 128
Neben den vereinfachten, verlustfreien Konvertierungen schärft das aktuelle JEP vor allem die Dominanzregeln im switch weiter. Sie stellen sicher, dass kein case unerreichbar ist, weil ein vorheriges Pattern bereits alle möglichen Werte abdeckt. Der Compiler erkennt solche Situationen inzwischen zuverlässiger und meldet sie als Fehler. Zusammen mit den bereits eingeführten Pattern-Typen ist das ein wichtiger Schritt hin zu einer konsistenteren und deklarativeren Sprache. Entwicklerinnen und Entwickler können Datenstrukturen direkt auswerten, Boilerplate-Code reduzieren und komplexe Fallunterscheidungen klarer formulieren. Weitere Mustertypen wie Array Patterns oder die Dekonstruktion beliebiger Klassen (nicht nur Records) sollen in zukünftigen OpenJDK-Releases folgen.
Die Structured Concurrency reift weiter
Die Einführung von Virtual Threads in Java 21 [9] hat die Nebenläufigkeit in Java deutlich vereinfacht. Doch diese schlanken Threads allein lösen noch nicht alle strukturellen Probleme paralleler Programme. Wie werden mehrere Aufgaben gemeinsam orchestriert? Was passiert, wenn eine Teilaufgabe fehlschlägt? Und wie stellt man sicher, dass keine Hintergrund-Tasks unkontrolliert weiterlaufen? Genau hier setzt die Structured-Concurrency-API an. Das Feature kam ebenfalls erstmals als Preview in Java 21 und erscheint in Java 26 mit JEP 525 [10] in der sechsten Preview. Nachdem es in Java 25 größere Änderungen an der API gab, dient die aktuelle Iteration vor allem dazu, weitere Erfahrungen aus der Praxis zu sammeln und das API-Design zu stabilisieren.
Klassische Java-Anwendungen starten parallele Aufgaben häufig über ExecutorService und Future:
Dieses Modell bringt einige Nachteile mit sich: Die Fehlerbehandlung ist fragmentiert, Tasks können weiterlaufen, obwohl andere bereits fehlgeschlagen sind, und die Lebensdauer der Aufgaben ist nicht klar an einen Scope gebunden. Structured Concurrency verfolgt einen anderen Ansatz: Parallele Aufgaben werden innerhalb eines gemeinsamen Lebenszyklus gestartet und verwaltet. Ähnlich wie bei try-with-resources ist damit klar definiert, wann Tasks beginnen und wann sie garantiert beendet sind:
Alle gestarteten Tasks gehören hier zu einem gemeinsamen Scope. Schlägt eine Aufgabe fehl, werden die anderen automatisch abgebrochen. Nach Verlassen des try-Blocks ist garantiert, dass keine Tasks weiterlaufen. Ein wichtiger Bestandteil des Konzepts ist die zentrale Fehlerbehandlung. Statt Exceptions einzelner Tasks separat zu behandeln, führt join() die Fehler des Scopes zusammen. Wenn ein Task fehlschlägt, löst join() eine StructuredTaskScope.FailedException aus, die die ursprüngliche Exception der fehlgeschlagenen Subtask kapselt. Gleichzeitig werden verbleibende Tasks abgebrochen.
Sogenannte Joiner definieren, wie Ergebnisse der Subtasks kombiniert und wie Fehler oder Zeitüberschreitungen behandelt werden sollen. Häufig verwendete Strategien sind bereits als Fabrikmethoden vorhanden, etwa Joiner.awaitAllSuccessfulOrThrow() (Default-Joiner) oder Joiner.anySuccessfulOrThrow(). Außerdem kann man einfach eigene Joiner implementieren. Java 26 führt zudem den Callback onTimeout() ein. Damit können Anwendungen entscheiden, wie sie mit Zeitüberschreitungen umgehen – etwa indem sie nur die bis dahin erfolgreichen Ergebnisse zurückgeben.
Ihre volle Stärke entfaltet die Structured Concurrency in Kombination mit Virtual Threads. Jede Aufgabe kann ohne komplexes Thread-Pool-Management in einem eigenen Virtual Thread laufen. Das ermöglicht ein Programmiermodell, das synchron wirkt, intern aber stark parallel skaliert. Gerade in Backend-Architekturen eignet sich dieser Ansatz für typische Muster wie parallele Serviceaufrufe, Datenaggregation oder Fan-Out/Fan-In-Strukturen. Structured Concurrency verbindet eine hohe Skalierbarkeit mit einem deutlich verständlicheren Programmiermodell für nebenläufige Anwendungen. Komplizierte und fehleranfällige Alternativen wie reaktive Programmierbibliotheken oder manuelle Thread-Verwaltung werden damit überflüssig.
Vector API: SIMD für Java
Ein weiteres langfristiges Performance-Projekt setzt Java 26 mit JEP 529 fort [11]: die Vector API. Sie erscheint inzwischen zum elften Mal im Inkubator-Status und gehört damit zu den langlebigsten experimentellen Features der letzten Jahre.
Ziel der Vector API ist es, SIMD-Instruktionen (Single Instruction, Multiple Data) aktueller CPUs direkt aus Java heraus nutzbar zu machen. Dabei lassen sich mehrere Werte in einem einzigen CPU-Befehl parallel verarbeiten. Diese Technik spielt eine wichtige Rolle in Bereichen wie numerischen Simulationen, Bildverarbeitung, Signalverarbeitung oder Machine-Learning-Algorithmen. Ein einfacher Vergleich zeigt den Unterschied. Ohne Vector API erfolgt die Verarbeitung der Werte in einer Schleife:
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
Mit der Vector API lassen sich mehrere Werte gleichzeitig berechnen:
Listing 11: SIMD-Instruktionen mit Vector-API
```java
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
Die Breite der Operation hängt von der CPU ab – beispielsweise 128 oder 256 Bit. Der JIT-Compiler kann diese Operationen direkt auf die SIMD-Instruktionen der jeweiligen Hardware abbilden. Die Vector API ist strategisch wichtig für datenintensive Anwendungen, etwa für Vektorberechnungen in Datenbanken, Embedding-Vergleiche in KI-Systemen oder andere numerische Workloads. Allerdings wartet sie noch auf eine wichtige Grundlage: Project Valhalla und die geplanten Value Types. Erst mit einem kompakteren Speicherlayout für Werte kann die API ihr volles Potenzial entfalten. Auch wenn die Vector API weiterhin im Inkubator bleibt, zeigt ihre kontinuierliche Weiterentwicklung deutlich, wohin sich die Plattform bewegt: Java soll aktuelle Hardware effizient ausnutzen können und auch für stark daten- und rechenintensive Anwendungen wie KI konkurrenzfähig bleiben.
Wichtiger Baustein in der langfristigen Entwicklung
Java 26 ist kein spektakuläres Feature-Release, aber ein wichtiges Puzzlestück in der langfristigen Weiterentwicklung der Plattform. Viele Änderungen wirken auf den ersten Blick klein, bereiten jedoch größere Entwicklungen vor. Eine der wichtigsten Baustellen bleibt Project Valhalla, das mit Value Types das Typsystem von Java grundlegend erweitert. Value Types versprechen kompaktere Datenstrukturen ohne Objekt-Header, bessere Cache-Lokalität und weniger Druck auf den Garbage Collector. Gerade für numerische Anwendungen, Datenverarbeitung oder KI-nahe Workloads wird das erhebliche Performancegewinne bringen. Jüngsten Gerüchten zufolge könnten Value Classes bereits im Sommer 2026 in das OpenJDK-Projekt einfließen und mit Java 28 im März 2027 erstmals als Preview-Feature erscheinen.
Parallel dazu entwickelt sich das Sicherheits- und Integritätsmodell der Plattform weiter. Unter dem Leitgedanken „Integrity by Default“ gibt es Einschränkungen für Mechanismen, die Objektinvarianten über Reflection oder unsichere APIs umgehen können. Ziel ist ein stabileres und besser optimierbares Objektmodell. Die Neuerungen in Java 26 zeigen eine klare Richtung: Die Plattform wird systematisch moderner – von der Sprache über das Nebenläufigkeitsmodell bis hin zur Runtime und den Netzwerkprotokollen. Dabei bleibt Java seinem bewährten Ansatz treu, größere Veränderungen schrittweise einzuführen und möglichst abwärtskompatibel zu bleiben.
Neben den vorgestellten zehn JEPs enthält Java 26 zahlreiche kleinere Verbesserungen. Details dazu finden sich in den Release-Notes [12]. Änderungen an der Java-Klassenbibliothek lassen sich zudem sehr übersichtlich im Java Almanac [13] nachvollziehen, der die Unterschiede zwischen den JDK-Versionen auflistet. Und auch ein Blick nach vorn lohnt sich: Im JEP-Index unter Draft and submitted JEPs [14] sammeln sich bereits zahlreiche Ideen für kommende Java-Versionen.
URL dieses Artikels: https://www.heise.de/-11213403
C++26 kommt und führt unter anderem die Kompilierungszeit‑Reflexion ein, die einige Aufgaben vereinfacht, ohne auf Makros zurückgreifen zu müssen.
Im heutigen Beitrag meines C++-Blogs möchte ich über C++26 und eine der wahrscheinlich wirkungsvollsten Funktionen schreiben, die dem Arbeitsentwurf hinzugefügt wurden. Auch wenn C++26 noch ein paar Wochen bis zur offiziellen Fertigstellung braucht, wissen wir seit dem WG21-Sommertreffen im Juni 2025, was in C++26 enthalten sein wird.
Der neue Standard wird viele spannende Verbesserungen bringen, aber die wahrscheinlich größte Veränderung ist die Reflexion (Reflection) zur Kompilierungszeit! In Sofia hat das Standardisierungs-Komitee sieben Reflection-Papiere für C++26 angenommen:
Die verlinkten Beiträge bieten genügend theoretischen Lesestoff.
Kommen wir zur Praxis
Die wichtigste Frage ist: Was kannst du mit dieser neuen Funktion machen? Einige haben bereits ihre Ideen veröffentlicht.
Steve Downey [8] hat ein Beispiel, das eine JSON-Zeichenkette zur Kompilierungszeit analysiert und daraus C++-Objekte erstellt. Der direkte Link zum Compiler Explorer lautet godbolt.org/z/YsEK418K6 [9].
Das zweite Beispiel stammt von Jason Turner [10] und ermöglicht es, Bindungen zu anderen Sprachen zu generieren. Der direkte Link zum Compiler Explorer lautet godbolt.org/z/6Y17EG984 [11].
Ich finde beide Beispiele prima, aber will auch ein eigenes zeigen. Das Problem, das ich jahrelang zu lösen versucht habe und das auch in verschiedenen Schulungen und sogar in meinem eigenen Buch Programming with C++20 – Concepts, Coroutines, Ranges, and more [12] auftaucht. Ich musste die bittere Pille schlucken, einen nicht so tollen Code zu zeigen.
Reflexion, Reflexion an der Wand, was kann ich mit dir alles machen?
Ich rede von Enums und nicht davon, wie man ein Enum in einen String konvertiert und umgekehrt. Der Code dafür ist übrigens in den oben verlinkten Beiträgen zu finden.
Nein, ich hab mindestens noch ein anderes Problem mit Enums: Iteration. Wie oft wollte ich schon über ein enum iterieren. Es gibt Lösungen, die meist makrobasiert und mit vielen Regeln sind. Zum Beispiel nur aufeinanderfolgende Zahlen und ein letztes Mitglied namens Last oder MAX. Aber was ist, wenn es Lücken in einem enum gibt? Wie
enum class Color { Transparent, Red = 2, Green, Blue = 8, Yellow };
Genau, dann greift die Regel, dass nicht aufeinanderfolgende Nummerierungen nicht erlaubt sind.
Folgender Code zeigt einen Ansatz, der anderen Sprachen wie C# ähnelt, in denen das Iterieren der enum-Werte ohne weitere Umstände möglich ist:
Ich habe in #A eine Hilfsvariable erstellt, einfach weil es für sich schon hilfreich ist, die Anzahl der Werte in einem enum zu ermitteln.
Die Implementierung für die Aufgabe selbst befindet sich dann in #B. Du kannst dir eine andere Implementierung ausdenken, die für größere Enums besser geeignet ist, aber diese hier ist schön kurz und bündig.
Die Utility-Funktion sieht in Aktion nicht besonders aus, und man merkt nicht, dass im Hintergrund eine Reflexion stattfindet:
for(const auto e : get_enum_values<Color>()) {
std::print("{} ", std::to_underlying(e));
}
std::println();
Wie du siehst, gibt #B den stark typisierten Enum-Wert zurück. Deshalb ist std::to_underlying erforderlich, wenn der Wert mit std::print verwendet wird. Das ist eine Designentscheidung: Der Code bleibt so lange wie möglich stark typisiert.
Es gibt noch weitere Designüberlegungen, beispielsweise ob get_enum_values auch eine Variable sein sollte, da sie für jeden Typ konstant ist.
An dieser Stelle werde ich nicht alle neuen Teile erklären, da ich nur zeigen möchte, was mit C++26 möglich ist.
P.S.: Falls du dich fragst, ob die Implementierung von #B für ein leeres enum, welches ein std::array der Größe Null ergibt, korrekt ist, lautet die Antwort: Ja, der Code ist korrekt. Einer der Vorteile von std::array ist, dass es einen Sonderfall für den Fall der Größe Null gibt. Ein Array im C-Stil wäre nicht gültig.
URL dieses Artikels: https://www.heise.de/-11157616
Software Testing: Effektives Testreporting ohne Overhead
Von Heise — 17. März 2026 um 10:26
(Bild: Richard Seidl)
Richard Seidl spricht mit Matthias Groß über Testreporting und dessen Umsetzung im Projektalltag.
In dieser Folge spricht Richard Seidl mit Matthias Groß über Testreporting und dessen Umsetzung im Projektalltag. Im Fokus steht eine pragmatische Herangehensweise: Statt überladener Dashboards setzt Matthias Groß auf eine klare 3x3-Matrix und automatisierte Datenaufbereitung mit Python und Excel.
Die beiden beleuchten, wie Testreporting nicht nur den Status sichtbar macht, sondern auch als Führungsinstrument genutzt werden kann. Das Gespräch zeigt, wie wichtig Zieldefinition, Datenqualität und flexible Sichten sind. Besonders spannend sind die Einblicke zu KI-Experimenten im Reporting und die ehrlichen Reflexionen darüber, was wirklich zählt.
Matthias Groß [2] ist Partner der TestGilde GmbH und seit 2007 als Berater für Softwarequalitätssicherung und Testmanagement tätig. Seine Schwerpunkte liegen im operativen Testmanagement, der Einführung und Weiterentwicklung von Testmanagementstrukturen sowie der Betreuung kundenspezifischer Testservices. Er engagiert sich zudem an der Dualen Hochschule Baden-Württemberg, ist Mitgründer der Testcommunity The TestLänd [3] und Mitglied des Programmkomitees des QS-Tags.
Software Testing im Gespräch
Bei diesem Format dreht sich alles um Softwarequalität: Ob Testautomatisierung, Qualität in agilen Projekten, Testdaten oder Testteams – Richard Seidl und seine Gäste schauen sich Dinge an, die mehr Qualität in die Softwareentwicklung bringen.
Nvidia attackiert mit dem ARM-Serverprozessor Vera auch AMD und Intel
Von Heise — 17. März 2026 um 19:01
Server-Racks mit bis zu 22.528 CPU-Kernen: Nvidias Vera-CPU mit Olympus-Kernen kommt nicht nur im Gespann mit KI-Beschleunigern auf den Markt.
Nvidias ARM-Serverprozessor „Vera“ mit selbst entwickelten ARM-Kernen soll in den Revieren von AMD Epyc und Intel Xeon räubern. Denn Nvidia kombiniert Vera nicht nur mit dem KI-Beschleuniger „Rubin“, sondern baut auch reine CPU-Systeme damit.
Auf der Hausmesse GTC hat Nvidia für das zweite Halbjahr 2026 auch ein „Vera CPU Rack“ angekündigt. In die wassergekühlte Ausführung passen Einschübe mit insgesamt 256 Vera-Prozessoren, die jeweils 88 Kerne haben. Insgesamt laufen in einem Rack dann 22.528 CPU-Kerne mit 45.056 Threads. Denn jeder der zu ARMv9.2 kompatiblen „Olympus“-Kerne verarbeitet zwei Threads gleichzeitig.
Mehr Kerne bei x86
Wenn es um die reine Anzahl von CPU-Kernen pro Rack geht, bieten AMD und Intel mehr. Beispielsweise Supermicro verkauft „Twin“-Server, die pro Höheneinheit (HE) zwei einzelne Server mit je zwei CPU-Fassungen enthalten. Damit lassen sich auf 40 HE insgesamt 160 physische Prozessoren unterbringen. In den wassergekühlten Versionen darf jeder bis zu 500 Watt verheizen, also 75 kW reine CPU-Leistungsaufnahme pro Rack.
Bestückt mit 160 AMD Epyc 9965 mit je 192 Zen-5c-Kernen [1] ergibt diese Konfiguration 30.720 CPU-Kerne und 61.440 Threads pro Rack. Schon mit dem 144-Kerner Intel Xeon 6780E wären 23.040 Kerne möglich, allerdings ohne Simultaneous Multithreading, weil das Intels E-Kerne nicht beherrschen. Dafür kommt der Xeon 6780E mit 330 Watt aus, die Version 6766E sogar mit 250 Watt. Vorzugskunden bekommen von Intel auch einen Xeon 6 mit bis zu 288 E-Kernen [2], also bis zu 46.080 pro Rack.
Modul mit zwei Nvidia-Vera-Prozessoren und je acht SOCAMM2.
(Bild: Nvidia)
Vera-Vorzüge
Nvidia führt mehrere Vorteile von Vera [3] im Vergleich zur Konkurrenz ins Feld und hat auch bereits Kunden: Unter anderem Meta will Vera einsetzen, aber auch Alibaba, Cloudflare, Nebius und Oracle Cloud Infrastructure (OCI).
Nvidia verspricht besonders hohe Effizienz der ARM-Kerne. Außerdem bindet Vera keine Registered DIMMs mit DDR5-SDRAM an, sondern acht SOCAMM2-Module [4] mit sparsamerem LPDDR5X-Speicher. Damit erzielt jede Vera-CPU eine Datentransferrate von rund 1,2 TByte/s und steuert bis zu 1,5 TByte Arbeitsspeicher an.
Vera gehört auch zu den ersten Prozessoren, die PCI Express 6.0 beherrschen. In der zweiten Jahreshälfte soll das allerdings auch bei AMD Venice [5] kommen.
Aufbau der Nvidia-CPU Vera mit 88 ARMv9.2-Kernen.
(Bild: Nvidia)
Hohe Singlethreading-Performance
Ohne bisher konkrete Benchmark-Ergebnisse zu veröffentlichen, verspricht Nvidia eine besonders hohe Singlethreading-Performance für die einzelnen Olympus-Kerne. Das soll für bestimmte Rechenaufgaben von KI-Workflows Vorteile bringen.
Auch Simultaneous Multithreading (SMT) setzen die Olympus-Kerne anders um als die x86-Kerne von AMD oder Intel. Nvidia spricht von Spatial Multithreading. Das soll die konkurrierenden Threads stärker voneinander isolieren und die Performance soll weniger stark schwanken als bei anderen SMT-Umsetzungen.
Nvidia kombiniert die Vera-Prozessoren in den eigenen Servern mit eigenen ConnectX-Netzwerkadaptern oder SmartNICs vom Typ BlueField-4. Dadurch lassen sich die Vera-Racks leicht mit KI-Beschleunigern von Nvidia kombinieren, für die Nvidia auch die Switches verkauft.
Auch andere Hersteller wollen Vera-Server verkaufen, etwa Dell, HPE, Lenovo und Supermicro. Sie verwenden das modulare System Nvidia MGX [6]. Es sind auch luftgekühlte Vera-Server und welche mit nur einem Prozessor (Single Socket) geplant.
URL dieses Artikels: https://www.heise.de/-11214715
Links in diesem Artikel: [1] https://www.heise.de/news/AMD-Server-CPU-Epyc-9005-Erster-Test-bestaetigt-hohe-Leistung-und-Effizienz-9976724.html [2] https://www.heise.de/news/Server-CPU-Clearwater-Forest-kommt-als-Xeon-6-mit-bis-zu-288-Kernen-10733568.html [3] https://developer.nvidia.com/blog/nvidia-vera-cpu-delivers-high-performance-bandwidth-and-efficiency-for-ai-factories/ [4] https://www.heise.de/news/x86-Steckmodul-fuer-Embedded-Systems-mit-wechselbarem-LPDDR5X-RAM-11207883.html [5] https://www.heise.de/news/AMD-zeigt-riesige-Chipkonstrukte-Epyc-Venice-und-Instinct-MI455X-11133033.html [6] https://www.nvidia.com/en-us/data-center/products/mgx/ [7] https://www.heise.de/ct [8] mailto:ciw@ct.de
Der erste Teaser zu Dune 3 zeigt den neuen Krieg. Und Pauls inneren Konflikt: Er darf nicht sterben – noch nicht.
Der dritte Teil kommt im Dezember in die Kinos.Bild:
Warner Bros.
Warner Bros. hat den ersten Teaser zu Dune: Part Three veröffentlicht. Der Film setzt die Geschichte von Paul Atreides fort und orientiert sich inhaltlich an Frank Herberts Roman Dune: Messiah.
Glücklichere Zeiten
Im Mittelpunkt steht, was nach Pauls Sieg über das Haus Harkonnen geschieht: Der ehemalige Rebellenführer übernimmt die Rolle eines religiösen Messias und stößt damit einen galaktischen Krieg an. Gleichzeitig geht er aus politischen Gründen eine Ehe mit Prinzessin Irulan (Florence Pugh) ein, was zur Trennung von Chani (Zendaya) führt. Der Teaser deutet sowohl die militärischen Konflikte als auch Pauls persönliche Krise an.
Zu Beginn zeigt das Material noch ruhige Momente zwischen Paul und Chani. In einer Szene sprechen beide über mögliche Namen für ein gemeinsames Kind – ein Detail, das Kenner der Buchvorlage als Vorausdeutung einordnen dürften. Danach wechseln die Bilder zu großangelegten Kriegsszenen und politischen Spannungen im Imperium.
Paul selbst steht dabei im Zentrum der Handlung. In einem Voice-over beschreibt er die Eskalation der Gewalt: Je mehr er kämpfe, desto stärker werde der Widerstand. Gleichzeitig sucht er Rat bei seiner Mutter Lady Jessica (Rebecca Ferguson), die ihn daran erinnert, worin sein Vater und er sich unterscheiden.
Neben bekannten Figuren wie Stilgar, dem Anführer der Fremen (Javier Bardem), zeigt der Teaser neue und erweiterte Rollen. Dazu gehören Alia Atreides, Pauls Schwester, sowie erstmals ein Blick auf den Antagonisten Scytale, gespielt von Robert Pattinson.
Villeneuve schließt seine Trilogie ab
Die Regie führt erneut Denis Villeneuve, der bereits die ersten beiden Teile der Reihe inszenierte. Dune: Part Three soll die Geschichte um Paul Atreides abschließen und stärker auf die Folgen seiner Machtübernahme eingehen.
Der Teaser endet mit einer kampfbereiten Version von Paul, der vor den martialischen Truppen steht und erklärt, dass er nicht sterben darf – zumindest noch nicht.
Autonomes Fahren: So kämpfen Tesla, Uber und Co um Vertrauen und Sicherheit
Von Peter Steinlechner — 17. März 2026 um 18:51
Eine Paneldiskussion zeigt, wie Entwickler, Betreiber und Behörden autonome Autos heute wirklich testen.
Cybercab von Tesla im Januar 2026 auf der Brussels Motor ShowBild:
JONAS ROOSENS/BELGA MAG/AFP via Getty Images
Auf der GTC 2026 wird beim Thema autonomes Fahren schnell klar: Die großen Visionen sind formuliert, jetzt geht es um Details, Daten und Risiken. In einer Paneldiskussion mit Vertretern von Nvidia, Tesla, Waabi, Motional, Uber und der kalifornischen Verkehrsbehörde DMV dreht sich alles um eine Frage: Wie lässt sich Sicherheit wirklich nachweisen?
Moderator Ali Kani, Automotive-Chef bei Nvidia, bringt die Herausforderung gleich zu Beginn auf den Punkt. Anders als bei KI-Textgeneratoren gehe es hier nicht um harmlose Fehler. "Wir wollen hier nie einen Fehler machen" , sagt er – schließlich gehe es um menschliche Sicherheit.
Zwischen den technischen Details wird ein größerer Trend sichtbar: Autonomes Fahren entwickelt sich zu einem der wichtigsten praktischen Einsatzfelder moderner KI.
Ashok Elluswamy, für die KI-Software bei Tesla zuständig, beschreibt offen, dass viele Methoden aus großen Modellen direkt übernommen werden. Training, Nachtraining und kontinuierliches Lernen ähneln stark den Verfahren aus Sprachmodellen.
Das Ziel formuliert er ungewöhnlich klar: Fahrzeuge seien der erste Schritt hin zu einer allgemeinen KI für die physische Welt. Es gehe nicht mehr nur um Fahrfunktionen, sondern um Systeme, die komplexe reale Situationen verstehen und darauf reagieren – mit all den Unsicherheiten der echten Welt.
Unterschiedliche Ansätze, gleiches Ziel
Die technischen Strategien bleiben dabei gegensätzlich. Elluswamy beschreibt Teslas Ansatz als radikal vereinfacht: Kameras statt Sensorfusion, ein durchgehendes neuronales Netz vom Eingang bis zur Fahrzeugsteuerung. "Wir haben das gesamte System end-to-end gemacht" , erklärt er.
Das auf autonomes Fahren für den Güterverkehr spezialisierte Unternehmen Waabi verfolgt eine Art Gegenentwurf. CEO Raquel Urtasun setzt auf Kamera, Lidar und Radar, um unterschiedliche Fehlerquellen abzufangen. "Diese Modalitäten haben sehr unterschiedliche Fehlerarten" , sagt sie.
Die Firma Motional (Level-4-Robotaxis) wiederum kombiniert mehrere Sensoren mit sogenannten Large Driving Models. CEO Laura Major betont vor allem die schwierigen Fälle: "Wir konzentrieren uns auf die wirklich harten Situationen."
Das könnte sein, wenn ein Fußgänger plötzlich zwischen parkenden Autos auf die Straße tritt, ein anderes Fahrzeug unerwartet einschert oder eine unübersichtliche Baustelle mit provisorischer Beschilderung und ungewöhnlichen Verkehrsführungen bewältigt werden muss.
Einigkeit herrscht bei der Validierung: Ohne Simulation geht es nicht mehr. Milliarden virtueller Kilometer, extreme Szenarien und gezielte Grenzfälle sind Standard.
Motional erzeugt bewusst Situationen, "die wir hoffentlich nie auf der Straße sehen" , und testet diese zusätzlich auf abgesperrten Strecken und im realen Verkehr.
Tesla nutzt dagegen riesige Mengen realer Fahrdaten. Seltene Ereignisse werden herausgefiltert und immer wieder abgespielt. "Man findet die Nadel im Heuhaufen und testet sie immer wieder" , beschreibt Elluswamy den Ansatz.
Mehrere Sprecher betonen, dass nur das finale Zusammenspiel aus Hardware und Software zählt. Wird das System verändert, verlieren frühere Tests einen Großteil ihrer Aussagekraft.
Validierung beginnt dann praktisch von vorn. Das erklärt, warum Fortschritte langsamer wirken, als viele erwarten: Jede Iteration zwingt zu neuen, aufwendigen Nachweisen.
Klare Regeln, langsamer Fortschritt
Miguel Acosta, Leiter für autonome Fahrzeuge beim California DMV, beschreibt den regulatorischen Rahmen. Seit mehr als zehn Jahren existiert ein dreistufiges System – vom Test mit Sicherheitsfahrer bis zum kommerziellen Einsatz.
Aktuell testen rund 30 Unternehmen, sechs davon ohne Fahrer. Nur drei sind im regulären Betrieb. Zentral ist der sogenannte Safety Case, also eine umfassende Begründung der Sicherheit inklusive Technik, Organisation und Prozessen.
Vertrauen entsteht nicht im Labor
Neben Technik und Regulierung entscheidet am Ende die Nutzererfahrung. Noah Zych, verantwortlich für autonome Mobilität bei Uber, beschreibt das pragmatisch: "Geben Sie den Leuten eine gute erste Fahrt."
Schon wenige Minuten könnten aus Skepsis Begeisterung machen – oder Vertrauen dauerhaft zerstören. Deshalb setzt Uber auf kleine Einsatzgebiete und vorsichtige Skalierung.
Die Diskussion zeigt vor allem eines: Autonomes Fahren ist kein einzelner Technologiesprung, sondern ein komplexer, iterativer Prozess. Neue KI-Ansätze, massive Simulationen und reale Tests greifen ineinander.
Anzeige: Roborock mit Wischfunktion kostet kurze Zeit nur 190 Euro
Von Benjamin Gründken — 17. März 2026 um 18:46
Bei Amazon gibt es einen Saugroboter mit Wischfunktion, den Roborock Q7 L5+, verdächtig günstig.
Wenn Sie auf diesen Link klicken und darüber einkaufen, erhält Golem eine kleine Provision. Dies ändert nichts am Preis der Artikel.
Saugroboter kosten nicht notwendigerweise ein kleines Vermögen.Bild:
Erzeugt mit ChatGPT; Amazon, Roborock; Montage: Golem.de
Saugroboter sind nicht grundlos so beliebt. Sie kommen zwar nicht in alle Ecken, halten die Wohnung aber weitgehend staubfrei. Damit ist schon sehr viel gewonnen, zumal sich der Staub dann auch nicht mehr so leicht auf Regalen und in den Ecken verteilt. Händisches Nacharbeiten ist nur noch selten erforderlich.
Hausarbeit mag des einen Hobby sein, sie nimmt den anderen aber die Zeit für Hobbys. Wer in Vollzeit arbeitet, den Haushalt vielleicht noch allein macht und Familie und Verpflichtungen hat, möchte seine knappe Freizeit nicht unbedingt mit Saugen verbringen.
Dankenswerterweise kosten Saugroboter dank des Konkurrenzkampfes zwischen Herstellern wie Roborock, Dreame und Xiaomi kein Vermögen mehr. High-End-Modelle mögen noch vergleichsweise teuer sein. Solide Einstiegsgeräte gibt es schon für unter 300 Euro. Besonders günstig ist aktuell der Roborock Q7 L5+. Bei Amazon ist er nun befristet für nur noch 189,99 Euro im Angebot.
Was kann der Roborock Q7 L5+?
Der Roborock Q7 L5+ ist angesichts seines Preises natürlich kein Spitzenmodell, aber für sein Geld auch überraschend gut ausgestattet. So verfügt er über eine Dockingstation, die den Staubbehälter automatisch in einen 2,7-Liter-Beutel entleert. Dadurch soll man je nach Nutzung bis zu sieben Wochen ohne Wechsel auskommen.
Dank HyperForce-Saugkraft erreicht der selbstfahrende Akku-Staubsauger laut Roborock 8.000 Pa. Damit soll er Staub, Krümel und Tierhaaren Herr werden. Der Roborock eignet sich laut Angaben für Teppiche, Hartböden und Fugen. Um zu verhindern, dass sich Haare verwickeln, gibt es das Dual-Anti-Tangle-System. Laut Hersteller soll dies den Wartungsaufwand minimieren.
Spannend: Obwohl der Q7 L5+ unter 200 Euro kostet, kann er nicht nur saugen, sondern gleichzeitig wischen. Drei einstellbare Wasserdurchflussstufen ermöglichen eine Anpassung an verschiedene Bodenarten. Derlei kommt natürlich weder mit einer Wiederbefüllung noch mit einer Heißlufttrocknung, ist in der Preisklasse aber auch nicht Standard.
Für präzise Karten ist die 360°-Lidar-Navigation zuständig. Mit einer Laufzeit von bis zu 150 Minuten lassen sich, so das Versprechen, auch größere Flächen abdecken. Hindernisse wie Türschwellen oder Teppichkanten sollen bis zu einer Höhe von 2 Zentimetern überwunden werden.
Preisfall nach Frühlingsangeboten
Wie man dem Preistracker Keepa entnehmen kann, kostete der Saugroboter bei Amazon während der gerade abgelaufenen Frühlingsangebote noch 249,99 Euro, Coupons und Gutscheine noch unberücksichtigt. Den aktuellen Preis, einmal mehr als befristetes Angebot markiert, gab es zwar in der Vergangenheit schon. Laut Preistracker lag Amazons 90-Tage-Schnitt allerdings noch bei 246,44 Euro. Der aktuelle Deal, bereitgestellt durch Roborock selbst und Versand via Amazon, gilt laut Produktseite
Wenn Sie auf diesen Link klicken und darüber einkaufen, erhält Golem eine kleine Provision. Dies ändert nichts am Preis der Artikel.